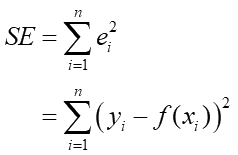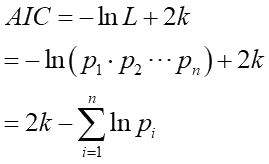VisualStudio + Pythonでディープラーニング
過学習の何が良くないのか?
(2019. 12. 19)
今回はディープラーニングというよりも「予測モデル」という分野において常に問題となる「過学習(オーバーフィッティング)」のお話です。
① フィッティングとは?
過学習、字面で見ると「学習し過ぎる」…。これ、別に良い気がしませんでしょうか?だって、学習いっぱいして賢くなる事はAIにとって良い事じゃんと。その気持ち、分かります。でも実はそこには落とし穴があるんです。結論から言うと、過学習したAIは本番に弱くなってしまうんです。
過学習は英語でオーバーフィッティング(Overfitting)と言います。フィッティングというのは、ある関数をデータに当てはめる事を言います。簡単な例を示してみます。今次のような直線の式があるとします:
例えば次のデータに対しこの直線を当てはめてみましょう:
x y 3 7 5 4
未知のパラメータがa,bの2つに対してデータが2つある場合、これは連立方程式で完全に解く事ができます(直線の場合)。実際傾きa=(7-4)/(3-5)=-3/2、切片b=y-ax=4-(-3/2)*5=23/2です。これは高校までの数学のお話。実際の世の中はそううまくは出来ていません。大抵は「何か直線ポイ感じがするんだよなぁ〜」みたいなこんなデータ群だったりします:
x y 3 5 5 3 1 6 8 2
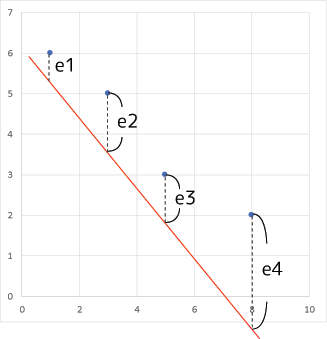
で、このちょっとよれよれな感じだけで直線的な感じがする点群に実際直線を当てはめるにはどうしたら良いか?という問題。これが「フィッティング問題」です。もちろん、この4点を通る1本の直線はありません。だって真っすぐに並んでいないんですから。なので「なるべく近くを通るような線を引く」という発想になる訳です。ではその「なるべく近く」というのをどうやって規定するのか?これには色々な考え方があるのですが、最もよく使われる理屈の一つが「最小二乗誤差」です:
直線はパラメータaとbがあれば引けます。なので適当なaとbを与えると上のように適当な直線を描く事が出来ます。この直線がどれだけデータ点に近いか知るために、各点から直線までのY軸方向の距離eiをそれぞれ計算します。各点のx座標は既知ですから、そのxに対応する直線上の点は簡単に求まります。よってeiも簡単に求まります。ただ、距離計算は最後にルートする必要があり計算が煩雑になるのと、統計的な性質の良さから実際は距離ではなくて「距離のべき乗」を計算します。そして、各べき乗距離を全部足して評価値とします:
この評価値の事を「二乗誤差」と言います。あとはこの値を最小にするようにパラメータaとbを探せば、少なくともこういう評価で点に最もフィットした直線が決まる事になります。そういう最も小さい二乗誤差の事を最小二乗誤差と言います。ちなみに、直線近似の場合最小二乗法であればパラメータa,bを解析的に求められます。そうやってフィットさせた直線の事を「回帰直線」と言います。
フィッティングには他にも色々な方法論がありますが、ここで重要なのは「二乗誤差が最小となるモデルが良い」と考えている理屈です。これ、一見するともっともに感じます。でも、これが過学習の罠なんです。
② もっとフィッティングする関数
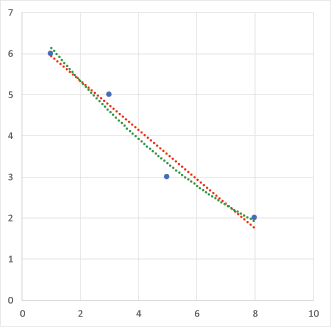
先ほどのグラフ上の点、何で直線フィッティングしたかというと「直線を使え」と言われたからです。でも、直線よりも曲線を使った方がもっと点に良くフィットするのではないでしょうか?例えば先程の点に対して直線近似と2次関数近似で見比べてみましょう:
…もっと分かりの良いデータ点にすれば良かった orz
えーと、実際に上のデータに対する直線と2次曲線の最小二乗誤差の値は以下のようになります:
関数 最小二乗誤差 直線 0.43 2次関数 0.29
2次曲線の方が誤差が小さいですよね。つまり全体的に見て直線よりもよりデータ点により近い感じの所を通っているという事になります。これ、どんな点群でも必ず直線より近い点を通る事になります。
じゃじゃあと言う事で、欲を出して3次関数にしたらどうでしょうか:
凄い、完璧にフィットしました。それは当然で、3次関数のパラメータ数は4つ、それに対してデータも4つなので連立方程式で解が一意に求まってしまうからです。この最小二乗誤差は、完璧にフィットしているのですから勿論ゼロです。
④ 過学習のヤバさ
さて、ここからが本番。では上のデータ点を表すモデルとして、3次関数が一番適切と言って良いでしょうか?「もっともフィッティングしているからそうじゃないの?」と思うかもしれません。でも、この点の揺らぎはもしかしたら測定の誤差が出ているだけなのかもしれません。そういう事は特に生データの測定時にはいくらでもありえますし、誤差無しで測定する事は通常不可能です。上の3次関数のフィッティングはそういう本来の値ではない本来無視したい誤差まで表現してしまっています。それって本当に良いモデルでしょうか?
統計学的には、そういう誤差まで表現してしまっているモデルは「良くないモデル」と判断されます。本来無視すべき所まで余計にフィッティングしてしまっている、この事を「オーバーフィッティング」、機械学習の世界では「過学習」と呼んでいるんです。
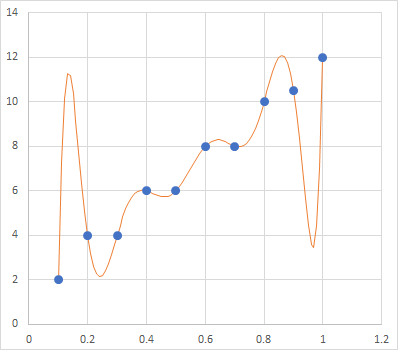
オーバーフィッティングのヤバさというのは点数の数に対してパラメータの数が近くなると顕著になります。例えばデータ点が10個あるある次の点群に9次関数を当てはめてみましょう:
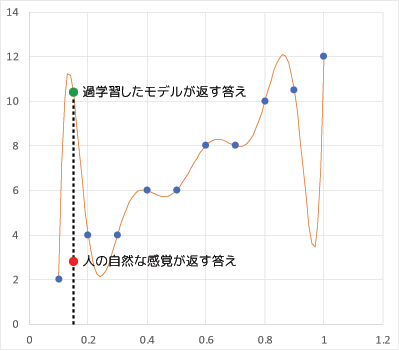
この直線的な点の並びに対してこの関数のフィッティングは明らかにおかしいですよね。このように過学習してしまったモデルを実践に投入して、例えばx=0.15辺りに対する答えを尋ねると、多分11位の値が返ってきます。同じ事を人がやるときっと3位の値を返すのではないでしょうか?どちらが自然かは言うまでもありません。過学習を起こしたモデルの推定値はちょっとヤバイのです:
⑤ ドロップアウト(Dropout)で過学習を回避
④までの例にあるように、データ数に対してモデルのパラメータ数が過剰にあると過学習を起こしやすくなります。理由はパラメータが沢山ある分モデルの形を細かく変化させやすくなってしまうからです(これを自由度と言います)。ニューラルネットワークでは層の数や構成によって変わりますが、パラメータ数は何百〜何十万という膨大な数になります。それだけ自由度があると嫌でも過学習になってしまいます。
過学習を防ぐ一つの有望な方法として「ドロップアウト」というのが考えられています。これは、学習している最中に層から出力される値を意図的にゼロにして無効化する(刺激として認識しなくする)事で間接的に学習データを疎にします。過学習になるのは元のデータにべったりフィットしてしまうのが原因ですから、そのデータを疎にする事で疑似的にデータをぼかす事が出来ます。結果としてそのぼやけた所に沿うようなモデルの形状になります。ノイズが入った画像をぼかすと雑味が緩和されるのと同じで、これは過学習で元データに依存してしまった乱高下するモデルよりは実は真に近いモデルになります。
Kerasでも勿論ドロップアウトを設定できます。具体的な方法は次の章で試してみる事にします。
⑥ L1正則化、L2正則化で評価にペナルティーを
過学習を回避する方法として他に「L1正則化」「L2正則化」という方法も考えられています。これは評価関数に推定された重みから計算されるペナルティーを加える事で評価を下げます。L1正則化重みの絶対値の合計を、L2正則化は重みのべき乗の合計を評価値に加えます。もし重みが大きく揺らいでいたら、絶対値もべき乗値も大きくなってしまうため評価値が相対的に下がります。よってこれらの正則化を用いるというのは「全体的な重みの揺らぎを下げる」という事を意味します。いわゆる「エントロピーを下げる」という概念ですね。
Kerasはこれらもサポートしています。過学習は避けるべき課題であるため、規模の大きいディープラーニングではこれらも多分必須です。なので後々の章で意味合いや使い方を掘り下げます。
⑦ 余談:適切なパラメータ数の判断
ここからは完全に与太話なのでドロップアウトの設定の仕方を見たい方は次の章へ進んで下さい(^-^;
今回のお話を書いていて大学で使っていた「情報量」の事を思い出したので触り程度お話しできればと。
この章の点群を表現するモデルとして直線、2次関数、3次関数という候補がありました。これらの点への近さは最小二乗誤差で判断出来ます。しかし、誤差が小さい事が必ずしも良い事では無い事も見てきました。では、どのモデルが適切なのでしょうか?それを判断する一つの方法として、統計学には「情報量」という基準が設けられています。ザックリ言えば「基本的に誤差が少ないモデルがえらいけど、同じような誤差だったらパラメータ数が少ないモデルがよりエライ」というノリの物です。もちろんバックボーンは厳格な統計学で記述されています(^-^;。
情報量の中で特に有名なのが赤池情報量規準(AIC:Akaike's Information Criterion)で、モデルの当てはまりの良さを次の計算で数値化します:
Lは「最大尤度」という誤差から求められる指標値で、kはモデルに使われるパラメータ(自由パラメータ)の数です。AICはフィッティングさせたモデル毎に1つ算出され、その値が一番小さいモデルを選択するのが良いとされます。何の事やらさっぱりかもしれませんので、ちょっと細かく説明しますね。
一般に(必ずでは無いですが)誤差というのは真の値から離れる程その出現頻度が少なくなります。幾つか条件があるものの、その離れ具合は概ね正規分布(Normal
Distribution)に従う事が経験的に知られています。模式的にイメージするならこういう感じです:
この正規分布の高さは「確率密度」という頻度のような値になっています。ある誤差に対しては特定の確率密度が存在します。値が大きい程良く出現するという感覚で捉えれば概ねOKです。で、この確率密度値をすべての誤差について掛け合わせたものを「尤度」と呼んでいます(注意:厳密な定義からはちょっと外れています)。概念的には「そういう誤差が同時に起こる確率」に相当します。もし真の値となるモデルの線と誤差とが大きく外れていたら、その誤差の確率密度は小さい値ばかりになってしまい、尤度もうんと小さな値になってしまいます。ですからその尤度が最も大きくなると良くフィッティングしていると言えます。そういう尤度を「最大尤度」と言います。
AICのLにはその最大尤度の値が入ります。尤度は確率密度pの掛け算でした。よってLの正体は沢山の確率密度の掛け算です。ところで対数の中の掛け算は対数の足し算に分解できるのでした。ここからAICは、
と計算出来ます。誤差の確率密度の対数を全部足せば良いのですから簡単です。こうして求めた各モデル毎のAIC値のうち最も小さい値になったモデルを選択すると概ね良い感じのモデルとなります。この式は当てずっぽうに出た訳では無くて、ちゃんと統計学的な裏付けがあるものです。科学論文などでモデル選択をする時に多用されています。ただデータの数が少ないと偏りが出るため、その偏りを補正したc-AICなど亜種も沢山あります。
ディープラーニングではパラメータ数が平気で何千という数になります。それだけの巨大モデルでこのAICが役に立つか、僕には良く分かりません。これと同じ概念を持っているのが先に挙げたL1正則化、L2正則化です。それらについても調べが付いたら記事化したい所です。