VisualStudio + Pythonでディープラーニング
CNNを実験してみよう
(2020. 1. 4)
前章で畳み込みニューラルネットワーク(CNN)の概要を押さえましたので、ここではCNNを使って実験をしてみましょう。理屈は動いてこそ実用です(^-^)
① 「A」と「B」を「C」判別する
入力画像内にあるAとBとCを識別して「これはA」「これはB」「これはC」と判断するモデルを作ってみます。画像サイズは32×32くらいでしょうか。まずはモデルの構成です。
画像は32×32×[色数C]の3次元配列です。これをそのまま特徴抽出ニューロンがある畳み込み層(Convolution Layer)に入力します。特徴抽出ニューロンの大きさは3×3の矩形にしておきます。各重さwはReLU活性化関数を通して非線形に対応できるようにしておきます。次にその結果を扱いたいのですが、解釈しやすくするため3次元配列を1次元に直します。これはFlatten層という層を挟むと実現出来ます。出力層ではA、B、Cの3カテゴリーに分類します。カテゴリー分類なのでSoftmaxを活性化関数に使います。モデル図はこんな感じでしょうか:
これをKerasでモデリングしてみましょう。
② Conv2D層
Kerasには畳み込みを行ってくれるConv2Dレイヤーが用意されています。この層を挟むだけで前章で説明したいかにもめんどくさそうな畳み込み処理を行ってくれるのですからありがたいもんです;
Conv2D(
filters,
kernel_size,
strides = (1, 1),
padding = 'valid',
data_format = None,
dilation_rate = (1, 1),
activation = None,
use_bias = True,
kernel_initializer = 'glorot_uniform',
bias_initializer = 'zeros',
kernel_regularizer = None,
bias_regularizer = None,
activity_regularizer = None,
kernel_constraint = None,
bias_constraint = None,
**kwargs
):
引数の内Denseには無いConv2D用の物を簡単に説明します。
〇 filters
特徴抽出ニューロンの個数を指定します。これは必須パラメータです。
〇 kernel_size
特徴抽出ニューロンの矩形縦横サイズを2次元のタプルで指定します。3x3なら(3,3)です。これも必須パラメータです。
〇 strides
特徴抽出ニューロンを動かす幅をタプルで指定します。デフォルトは(1,1)で1ピクセルずつ移動します。これを(2,2)などとするとその分スキップして動きます。飛び飛びにするほど出力画像は小さくなりデータが軽くなりますが、その分情報量は減ります:
〇 padding
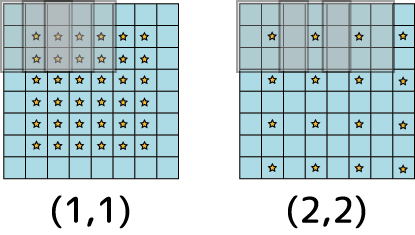
画像の縁辺にゼロの領域を追加します。これは特徴抽出ニューロンが畳み込みする時に縁辺のピクセルの情報量が欠落してしまうのを回避するために設けられています。設定できるのは'valid'と'same'で、sameにするとゼロ領域が追加されて縁辺ピクセルもそれ以外のピクセルと同じ重複度で計算に使用されるようになります。以下にvalidとsameの模式図を示します:
ストライドサイズが1の場合ですが、validを指定すると元の画像から縁辺を除いたサイズの畳み込み画像が出力されます。欠落というのはそういう意味です。sameの方は縁辺にゼロ領域が追加されるため、元の画像と同サイズの畳み込み画像が出力されます。
〇 data_format
入力される画像の情報であるinput_shapeでチャンネル数の位置がどこにあるかを指定します。指定できるのは'channels_last'と'channels_first'で、lastを指定した場合はinput_shapeは(batch, width, height, channels)、firstを指定すると(batch, channels, width, height)という順番になります。指定なし(None)にするとchannels_lastが使われます。
〇 dilation_rate
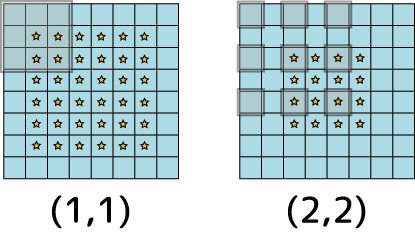
特徴抽出ニューロンの間に隙間を作ります。デフォルトの(1,1)だと隙間は無しですが(2,2)以上にするとその分隙間が広くなります:
入力される画面の縦横サイズが大きい場合、特徴抽出ニューロンの範囲が小さ過ぎると特徴が局所的過ぎる事があります。かといってニューロンの範囲を広げると処理負荷が高くなります。そこでdilation_rateを広げる事である程度高域で傾向を捉えた畳み込み画像を出力しつつ処理負荷も押さえます。
③ Flatten層
2次元以上の入力データを1次元のデータに変換するのがFlatten層です:
Flatten(
data_format = None,
**kwargs
):
引数のdata_formatはConv2Dのとまったく一緒です。これにより画像データはピクセル数次元なデータとなり次の層のニューロンへ送られます。
④ 「A」と「B」と「C」の学習画像をどう集めるか…
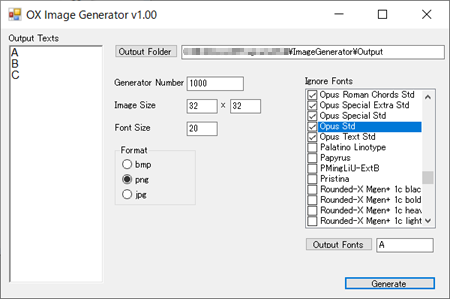
ここまででKerasでモデルは組めそうです。問題は学習データとなる画像です。A,B,Cの絵が描かれた32×32の画像、そしてその画像には正解となるタグが付いていないといけません。NMISTのデータは0〜9までの数字なのでアルファベットは無いし…。これはもう自分で作るしかないかなぁ。という事で画像を作ります。勿論手作業だと死ぬので自動化です。Visual C#で.Net Frameworkを通して大量の画像を作ってみます。
<超作業中!>
…出来ました(^-^;。こんなツールで大量のABC画像をゲットです:
この画像をPythonで読み込んで学習させます。
⑤ 実験!
それではKerasで実験してみましょう。④で用意した画像をPythonで読み込むには色々な方法がありますが、Kerasを使うのなら「Keras.preprocessing.image」モジュールを使うのが楽です。イメージを読み込むところだけを書いてみます:
#指定フォルダ下の画像ファイルを列挙
def getFilePathes( folderPath, ext ):
outFiles = []
for _, _, fileNames in os.walk( folderPath ):
for fileName in fileNames:
if fileName.endswith( ext ):
outFiles.append( os.path.join( folderPath, fileName ) )
return outFiles
#画像ファイルから色の配列を作成
def loadImageFrom( folderPath, x, y, tag ):
for fileName in getFilePathes( folderPath, ".png" ):
img = image.load_img( fileName, target_size=(32,32), color_mode='grayscale' )
x.append( image.img_to_array( img ) )
y.append( tag )
Kerasのimageモジュールは指定のパスにある画像ファイルを読み込んでその色情報をNumpyの配列にしてくれます。上のloadImageFrom関数の中で呼んでいるload_img関数はfileNameに画像ファイルへのパスを、target_sizeにはその画像からどういうサイズの画像を生成するのか(拡縮)、color_modeには画像の色変換を指定します。戻り値はPIL(Python Image Library)形式のイメージです。ここから色の配列だけ取り出すにはimage_to_array関数を通します。上の例の場合、32×32×1という3次元の配列が出来ます。最後の1は元々がRGBのPNG画像をグレースケールにしたため色情報が0〜255.0の1次元になったからです。
画像イメージは特定のフォルダ下に格納されています。そこからファイルパスを列挙するのがgetFilePathes関数です。戻り値はファイルパスの配列なのでそのままfor文に使う事が出来ます。
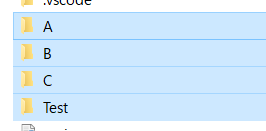
画像フォルダの構成は以下の通りです:
A,B,Cが学習用の画像が入ったフォルダです。今回は各3000枚用意しました。Testフォルダにはテスト用の画像が数枚入っています。
上の関数と画像データを使った畳み込みニューラルネットワークの実験コードはこちらになります:
import os
import keras
import numpy
from keras.preprocessing import image
#指定フォルダ下の画像ファイルを列挙
def getFilePathes( folderPath, ext ):
outFiles = []
for _, _, fileNames in os.walk( folderPath ):
for fileName in fileNames:
if fileName.endswith( ext ):
outFiles.append( os.path.join( folderPath, fileName ) )
return outFiles
#画像ファイルから色の配列を作成
def loadImageFrom( folderPath, x, y, tag ):
for fileName in getFilePathes( folderPath, ".png" ):
img = image.load_img( fileName, target_size=(32,32), color_mode='grayscale' )
x.append( image.img_to_array( img ) )
y.append( tag )
#画像ファイルからテスト用の色配列を作成
def loadTestImageFrom( folderPath, x, y ):
for fileName in getFilePathes( folderPath, ".png" ):
img = image.load_img( fileName, target_size=(32,32), color_mode='grayscale' )
x.append( image.img_to_array( img ) )
y.append( fileName )
#ファイルから学習データを作成
train_x = []
train_y = []
loadImageFrom( "A", train_x, train_y, [1,0,0] )
loadImageFrom( "B", train_x, train_y, [0,1,0] )
loadImageFrom( "C", train_x, train_y, [0,0,1] )
train_x = numpy.asarray( train_x )
train_y = numpy.asarray( train_y )
#入力画像ファイルを正規化
train_x /= 255.0
#モデル作成
model = keras.Sequential()
#入力層はConv2D
conv = keras.layers.Conv2D( filters=5, kernel_size=(3,3), padding='same', activation='relu', input_shape=( 32, 32, 1 ) )
flatten = keras.layers.Flatten()
categoryLayer = keras.layers.Dense( units = 3, activation='softmax' )
model.add( conv )
model.add( flatten )
model.add( categoryLayer )
#確率的勾配降下法で検索、交差エントロピー誤差で評価
sgd = keras.optimizers.SGD( learning_rate=0.05 )
model.compile( optimizer=sgd, loss="categorical_crossentropy" )
model.summary()
#学習開始
model.fit( train_x, train_y, epochs=32 )
#テスト実施
test_x = []
test_y = []
loadTestImageFrom( "Test", test_x, test_y )
test_x = numpy.asarray( test_x )
test_x /= 255.0
res = model.predict( test_x )
print( test_y )
print( res )
最初に[A][B][C]というフォルダの下に入っているアルファベットの画像ファイルを一気に読み込んでいます。読み込んだ分だけタグ(答え)を設定する必要があるのでloadImageFrom関数の引数に渡しています。関数を抜けるとtrain_xには(32,32,1)という3次元配列の束が、train_yにはその答えとなるone-hotな答えが入ります。その後の作業が重要です。train_xはPythonの配列として初期化しているのでNumpyにはなっていません。そこでnumpy.asarray関数でNumpyの配列に変換しています。これをしないとモデルのフィッティングの所で例外が出てしまいます。そしてもう一つ、train_x内の画像データは0〜255.0の値になっているのですが、このままだとあまりうまく推定されません。そのためその幅を0〜1にするよう255で割り算しています。これを正規化と言います。
入力層はConv2Dにします。ニューロンの数は取り敢えず5個としました。特徴抽出ニューロンの縦横は3×3にしています。paddingは有りで、活性化関数は非線形に対応できるようReLUとしました。入力データの型であるinput_shapeは32×32×1だったのでそのように指定しています。畳み込み層であるConv2Dを抜けた後の画像データをFlatten層で1次元の配列に直し、それをカテゴリー分けするDence層へ渡しています。Dense層はA,B,Cの3カテゴリーに分けるのでunitsは3です。またカテゴリーなのでSoftmaxを活性化関数に使い出力を確率化します。
後はこれまでと大体一緒ですね。評価関数として交差エントロピーを使わなければならない所に注意です。
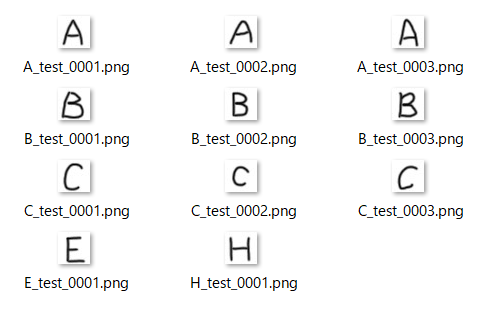
さて、このコードを実行すると学習が進みA,B,Cを識別できるモデルが育ちます。学習後テストとして手書きした以下のアルファベット画像を用意しました:
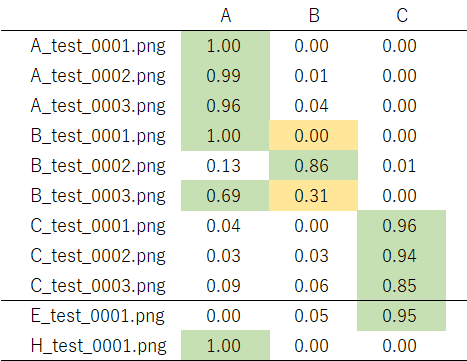
果たして上手に識別してくれるのでしょうか?実際にテストを通した結果がこちら:
緑色が最も確率が高いと識別したアルファベットで、黄色が正解の物です。これを見るとAとCはかなりしっかり判別してくれています!一方で「B」の識別率は今一ですね。ん〜惜しい所です。「E」と「H」はおまけとして入れてみました。EはCと判定しています。多分右側が開いている感じが似ているんでしょうね。HはAと判定しました。これはHの上が閉じている物を想像するとAっぽいですよね。その辺りを感じ取っているのかもしれません。
このように畳み込み層が1枚でもアルファベットをそこそこ判定してくれました。Bの判定率が低いのが残念ではありますが、実験としては中々楽しい結果になったのではないでしょうか(^-^)。