VisualStudio + Pythonでディープラーニング
Kerasの使い方をざっくりと
(2018. 11. 21)
前章でPythonによるディープラーニングの開発環境を整えました。本章では根幹ライブラリの一つである「Keras」について見ていこうと思います。非常に使いやすいライブラリですが、ディープラーニングの奥深さをそのまま反映しているので、この章では「兎に角なんか雰囲気掴みたい!」という目的でKerasをざっくり触ってみる事にします。
① Kerasとは?
KerasはPythonで書かれたニューラルネットワーク学習ライブラリです。ニューラルというのは「脳神経」の事、そしてネットワークは「網」の意味です。つまりニューラルネットワークとは脳神経の網状構造の事で、それをプログラム上で模倣して脳神経のような働きをさせてしまおうというがニューラルネットワークによるAI、そういう構造を学習によって作り上げるためのライブラリがKeras、という事です。
Kerasの公式HPはこちらです。ここに使い方などのドキュメントがまとめられています。Kerasの中にはニューラルネットワークを構築するためのモジュールが沢山用意されています。モジュールの意味と使い方を学んでいく事がKerasを学ぶことになります。ただ、Kerasパッケージは単体では動かす事は出来ません。バックエンドとしてTensorFlowなどの低レベルニューラルネットワークライブラリが必要です。その為TensorFlowなども一緒にインストールする必要があります。
② Sequentialモデル
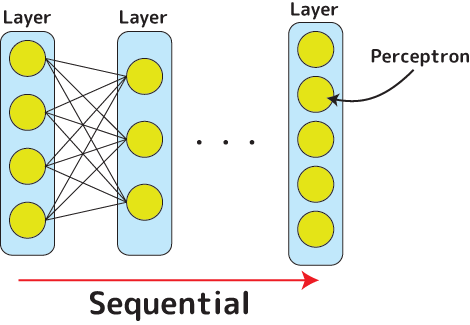
ニューラルネットワークは本来「網」なので、要素であるニューロン(神経)が文字通り網の目状に絡まっています。ただそういう構造は複雑で作る事が難しいため、構造(モデル)を簡略化します。その一つのモデルがシーケンシャル(Sequential)モデルです。シーケンシャルというのは「線形の」という意味で、線形というのは線のように一列につながっているという事です。その繋がる元は「レイヤー(Layer)」と呼ばれているニューロン(パーセプトロン(Perseptron))の塊です:
レイヤーの中にあるパーセプトロンが次のレイヤーに信号を送る。これをシーケンシャルに続けていき、最後のレイヤーまで届ける。この割と単純なモデルがシーケンシャルモデルです。Sequentialモデルにはこのレイヤーをいくらでも直列に追加する事が出来ます。
レイヤーにも色々な種類があります。Kerasには沢山のレイヤーの型が用意されています。その1つ「Dense(密になった物)」は上の図のように個々のパーセプトロンが次のレイヤーのすべてに繋がります(全結合ニューラルネットワークレイヤー)。Denseはもっとも良く使われるレイヤーです。
PythonでSequentialモデルを実際に作ってみましょう。直感的で分かりやすいものです:
import keras
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add( Dense( units = 16 ) )
model.add( Dense( units = 24 ) )
model.add( Dense( units = 10 ) )
まずkerasを使うのでimport kerasでそれを宣言します。TensorFlowもimportしても構わないのですが、明示しない場合はkerasが勝手にインポートしてくれます。
from keras.modelsというのはモデルが色々はいったモジュールです。その中から「Sequentialを使いますよ」というのがimport
Sequentialです。同様にレイヤーはkeras.layersにまとめられていて、その中のDenseを使う事を上で宣言しています。
何も設定されていない真っ新なSequentialモデルを作るには、単純にSequential()とします。括弧の中に初期化用の値を与える事も出来ますが、ややこしくなるので今は真っ新にしておきましょう。
続いてSequentialが持っているaddメソッドでレイヤーを追加していきます。上の例ではaddメソッドの引数にDenseレイヤーを与えています。そのDenseレイヤーも多様なパラメータで初期化できるのですが、最も単純な初期化が上のようにunitsに数値を与えるだけのものです。unitsには上の図の緑色のパーセプトロンのような最小単位の数を渡します。このunitsはDenseを作る時に唯一必須のパラメータです。
Denseは全結合するので、上のSequentialモデルの各レイヤーのユニットは次のユニットにすべて繋がります。ただし、上の初期化だとまだ不完全でして、このままだと何も出来ません。それは最初のレイヤーに「入力」する入り口が無いからなんです。実は最初のレイヤーだけは「入力シェイプ」と呼ばれる入力値と接続する入り口を設定する必要があります。
③ 入力シェイプ(input_shape)
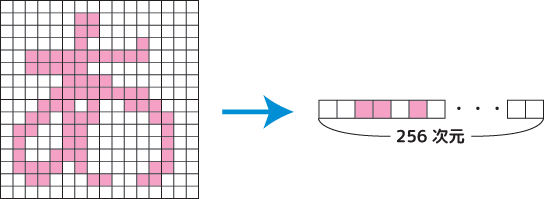
入力値とは解析したいデータそのものの事です。画像や文字、音声、地理データなどなど、様々なデータが考えられます。それらのデータは何らかのデジタル情報として数値化されています。例えば画像だったら全てのドットの色(R,B,G)ですし、文字列は文字ごとの文字コードに数値化されますね。ここで大切なのは、そういう数値化されたデータは「塊になっている」という点です。縦横16ドットの画像なら、そこには256個のドットがあり、一つのドットに一つの数値が適用されます。つまり数値が256個ある…。これを「256次元のデータ」と言います。通常入力値はこのようにN次元で塊になっています。
入力シェイプにはこの入力値の次元数を与えます。先のコードの最初のDenseに例えば256次元の入力シェイプを与えるには、次のように記述します:
import keras
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add( Dense( units = 16, input_shape = ( 256, ) ) )
model.add( Dense( units = 24 ) )
model.add( Dense( units = 10 ) )
input_shapeという引数には「タプル」という変更不可能な固定配列のような物を与えます。例えば(1, 3, 5, 7, 9)のように5つの要素を持つタプルは数値の羅列を()で包むと作れます。所が要素が一つしかない場合、(5)としてもこれはタプルとして認識されず単なる5という数字とみなされてしまいます。これをタプルと認識させるには(5, )のように後ろにコンマを付けます。つまり上の( 256, )というのは要素が1のタプルを意味しているんです。これでこのSequentialモデルは256次元のデータを受け入れる事ができるようになりました。
では2つ目以降のDenseにinput_shapeが無くて大丈夫なのか?となりますが、これは必要ありません。Denseは全結合ニューラルネットワークなので、自動的に次の全てのunitsに接続してくれます。
④ 訓練プロセスを作る(コンパイル:compile)
③までで入力に256次元のデータを受け付け、Denseが3つ線形に連なったSequentialモデルが出来ました。ただ作ったばかりのモデルは初期状態なので頭の中は真っ白。ここから脳のように振る舞うニューラルネットワークになるようレイヤーに含まれる各ユニット同士のつながりの強さを調整する必要があります。その為に「訓練(トレーニング、学習)」を行います。
人もそうですが、何かトレーニングする時最初は良く失敗します。失敗から原因を学び、それを修正して徐々に上手になっていきます。Sequenceモデルも同じで「失敗から原因を学ぶ」「修正」というプロセスを経る事で少しずつ上手になっていきます。ではそもそも「失敗」とは何か?それは正解じゃない事、もしくは正解からのズレです。犬の写真を見せて「猫」と答えたら、これは正解じゃないので失敗です。RGB=(100,
50, 30 )が正解の色に対して(90, 65, 32)という色だと言えば、それは(-10, +15,
+2)だけ正解からズレている事になります。これらのズレの大きさを定量化するのが「損失関数(loss
function)」と呼ばれる数学の式です。詳細は以後の章で検討していきますが、要は失敗度合いを数値化してくれる訳です。これによって「トレーニングAとトレーニングBでどちらがより正しかったか?」という比較を行えます。例えばAの結果が15、Bの結果が7なら、Bのトレーニングの方がより正解に近い振る舞いをした、と言えます。もし結果がゼロだったら完璧だったとなります。
失敗の比較ができると、そこから「より正解に近くなる考え方」を検討する事ができるようになります。トレーニングAからちょっと調整してトレーニングBをしてみたら正解に近くなった。であれば、トレーニングCはその調整方向をもっと推し進めれば良いのでは?っと考えるわけです。あるいは、調整してみたらかえって悪化してしまった、であれば逆方向に調整すると良くなるのではと推測するのも理にかなっている戦略ですよね。そういう正解に近づける修正方法の戦略を「最適化(Optimization)」と言います。失敗から学び修正する事で、Sequentialモデルはより正解に近づく賢い脳を得るのです。
このようにトレーニングにおけるズレを計る指標となる損失関数及び正解に近づける修正方法である最適化を選択するのが「訓練プロセスの作成」でSequentialが持つcompile関数で設定します。例えばこんな感じです:
model.compile( loss = 'mean_squared_error', optimizer = 'sgd' )
lossという引数が損失関数で、名前を文字列で指定します(もしくは誤差オブジェクトを直接指定)。上では「平均二乗誤差(Mean
squared error)」を指定しています。これは正解(平均値)からのズレの値を2乗して符号の影響を無くす方法です。またズレ幅が大きくなる程に失敗度合いがべき乗に大きいと判断します。例えば平均が5だとして7はズレ幅が+2なので誤差は(
7 - 5 )^2 = 4、一方3は( 3 - 7 )^2 = 16となり7よりも誤差がぐんと大きいと表現出来ます。
optimizerには最適化方法を名前で指定します(もしくは最適化オブジェクトを直接指定)。上のsgdというのは「確率的勾配降下法(Stochastic gradient descent)」の事で、その頭文字を取ったものです。何か難しそうな名前ですが概念は簡単で「正解からの誤差が大きい程逆方向により大きく調整してみよう」という最適化を取る戦略です。この概念自体は「再急降下法(Gradient
decent)」という部類なのですが、そこに「確率的」が付くと、トレーニングに用いるデータをランダムにシャッフルして与えるという方法が加わります。なぜシャッフルするのかなど詳細は追々検討しましょう。
損失関数も最適化も沢山の方法が用意されています。どの損失関数を選ぶか、どういう最適化戦略を取るかは重要なのですが、それにはそれぞれの特性を知る必要があります。この辺りはもう理論のお話なので粛々と学ぶしかありません(^-^;
⑤ 訓練開始!(フィッティング:fit)
訓練プロセス(コンパイル)を完了したら、いよいよモデルの学習を開始する事が出来ます。学習するためには「入力シェイプで指定した次元数がある入力データ」と「その入力データで期待する答え」が1対となったデータの配列が必要です。Kerasの慣習的に入力データはx_train、期待する答えはy_trainと表すようです。表でイメージするとこういう感じです:
配列 x_train y_train 0 3,7,5,1,6,...,2 30,15,2,...,5 1 3,8,0,3,2,...,7 42,23,6,...,11 ... ... ... n-1 1,7,4,5,5,...,9 19,54,22,...,18
x_train、y_train共に配列になります。学習させたいデータの総数(画像の枚数など)をn個とすると、x_train[0]には256次元のデータ列、y_train[0]にはその期待する答えがセットとなります。それがn個分ずらっと並びます。y_trainの答えが配列(マルチアウトプット)になっていますが、これはSequenceに加えた最後のDenseのユニット数と一緒でなければなりません。答えが例えば勝ち負けのようなカテゴリーであったり、何らかの平均値的な物である場合は単一の数になる事もあります(シングルアウトプット)。
上のようなデータ配列をpythonに用意してあげるわけですが、実はpythonのデフォルトの配列は使えません。ここで渡すのは「Numpy」というライブラリが提供する配列です。Numpyは多次元のベクトルや行列の演算を高速に行ってくれるライブラリで、kerasを組み込む時に一緒に導入されます。具体的に次のように配列オブジェクトを作成します:
import numpy
x_train = numpy.array( [ [ 3,7,5,(中略),2 ], [3,8,0,(中略),7 ], ... ] )
y_train = numpy.array( [ [30,15,2,(中略),5 ], [42,23,6,(中略),11], ... ] )
入力と出力(答え)のNumpy配列オブジェクトを用意出来たら、それをSequenceモデルのfitメソッドに与えると学習(訓練、フィッティング)してくれます:
history = model.fit( x_train, y_train, epochs = 15, batch_size = 30 )
引数のepochsというのは、x_trainの入力データ全部を1塊として、その塊を学習し直す回数を指定します。同じデータセットを何度も再学習させる事でモデル内のパラメータ(=重み)をそのデータセットに合うよう自動的に調整されます。具体的に何回回すのが良いかはケースバイケースですが、十分にフィッティングしたとみなせる状態になったらやめます。
batch_sizeはx_trainを小分けにする場合に与えます。その小分けにした1セットを「サブバッチ」と呼びます。これは「過学習」を防ぐ為です。過学習というのは、訓練用に与えたx_train専用のフィッティングになってしまう事を言います。過学習になってしまったモデルは訓練データに対しては抜群の成績を出しますが、本番のデータに対してはおかしな答えを出してしまいます。それでは本末転倒なわけです。そのため過学習を防ぐ手法が色々と開発されています。ミニバッチに分けるのもその防御策の一つです。
fitメソッドの戻り値はHistoryオブジェクトとなっています。これはフィッティングの結果を保持しています。詳細は追々見ていきます。
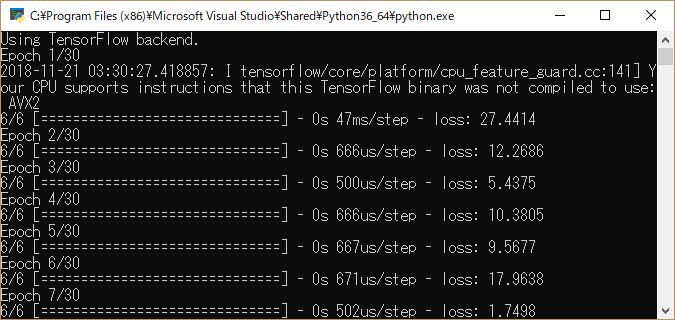
fitメソッドを実行すると、pythonのコンソール画面にその学習結果が1epoch毎に出力されてきます:
(上はテストで出した出力なので本編の説明とパラメータ数などが異なります)。
Epoch 3/30 はデータセットの繰り返し回数です。30回フィッティングを繰り返そうとしています。重要なのが「loss」という値。これはコンパイル時に引数で与えたloss(損失関数)が出した正解とのズレの値です。この値が小さい程訓練データに対して良くフィッティングしている事を意味します。出力を見るとepoch1では27くらいだったのがepoch2,3と数値がガンガン減っていますね。所がepoch4で数値が悪化してしまいました。これはパラメータ(重み)を微調整した結果良くない方向へ戻ってしまった事を表しています。そのパラメータ調整だとマズイので、内部では別の方向になるよう再調整が行われます。そういう事を繰り返して損失値がより小さくなるよう最適化を行っていくのです。
⑥ 本番!
さて、訓練を繰り返し良い感じになったモデルは、いよいよ本番に適用する段階になります。本番データの入力型は訓練データと一緒で指定次元の数値配列です。それをSequencialが持つpredictメソッドに与えます:
expect = model.predict( x_test, batch_size = 5 )
戻り値には本番データを解析した結果が出力配列の形式で返ります。単に結果を見たいだけならprint関数にポイと渡すだけでも見られます:
print( expect )
これでKerasによるニューラルネットワーク(ディープラーニング)の一番簡単な筋道は終わりです。こうして見てみると案外あっさりしていますよね。ただディープラーニングはまだまだ奥深い要素が沢山ありますし、何より「どういうデータと答えを用意して、モデルをどのように構築するか?」がディープラーニングの肝なので、ここからがスタートと言えるでしょう。