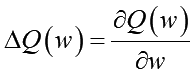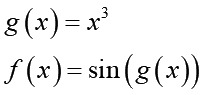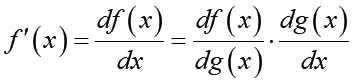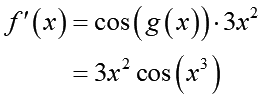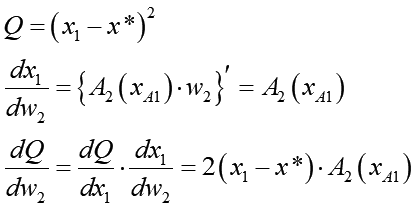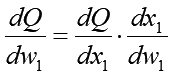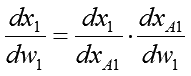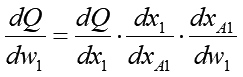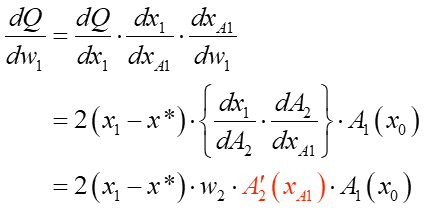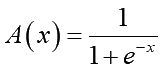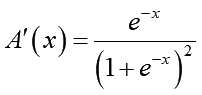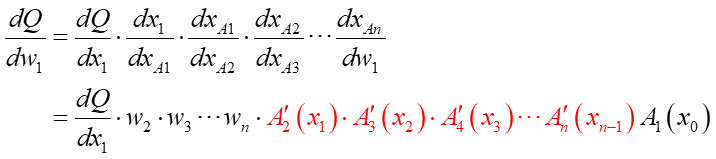VisualStudio + Pythonでディープラーニング
勾配消失問題とは?
(2019. 12. 5)
前章でKerasでデフォルトで使える活性化関数をざっと紹介しました。その中で度々「勾配消失問題がおこりやすい」などと解説を入れました。他のニューラルネットワークの解説サイトでも目にするこの「勾配消失問題(Vanishing Gradient Problem)」。いったいどういうものなのでしょうか?
① 何時まで経っても賢くならない問題
ニューラルネットワークでは与えられた入力刺激値から良い感じの出力刺激値を出してくれるようにニューロンの働きを調節する必要があります。具体的には入力刺激に変化を与える活性化関数A(x)、その結果をスケールする重みwを調整します。活性化関数は基本学習前に手動で与える物なので使い手の自由ですが、各ニューロンの重みwは繰り返し計算により自動的に最適な値に近づけるためブラックボックス的な調整項になります。この重みwを調整する方法として使われるのが「確率的勾配降下法(SGD)」です。
あるwからモデルの良さを表す評価値を計算する方法(評価関数)があるとします。色んなwに対応する評価値を算出すれば、例えば下のようなグラフが描けます:
横軸が重み、縦軸が評価値です。評価値の値が小さい程良いモデルだとして、最初の重みw0からスタートした場合、坂の下を転がるとより下の方に行ける事がわかります。この「坂のきつさ」は数学では「勾配」で表現されます。勾配は重みがちょっと変化した時に評価値がどれだけ変化するか、その割合です。日常の感覚でも急な坂道ってちょっと歩くとどんどん低くなります。これって「微分」の概念ですよね。そう、勾配は微分で表現できるんです。具体的には、
こんな感じの式になります。Q(w)は評価値を算出する関数です。評価関数がwで微分できる形であれば、具体的な勾配値を算出できる、という事です。
さて、とあるw0での勾配を求めたら、その値を使って次に調べるwを決定します。これは次のような式を使います:
ηは「学習率」というハイパーパラメータで勾配の値を増幅させます。勾配の値をη倍して重みから引く事で次の重みw1とする。これは坂の下の方へ突進するwの値へ移動したことになります(上の図のw0→w1の動き)。このw1からさらに同じ方法でw2、w3と重みを計算していくといずれ何らかの底に落ち着きます。これが確率的勾配降下法です。
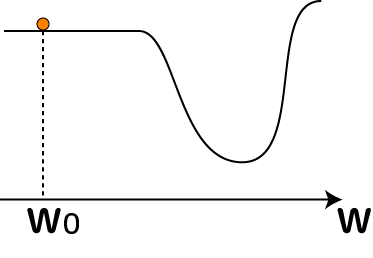
ところで、上の図のようないい感じの勾配であれば下方向へぴょんぴょん飛びながら底に落ち着くのですが、評価関数内に次のような平坦な箇所があったとしたらどうなるでしょうか?
ほら、右に良い所あるよ~、って言いたくなるんですが…(-_-;
勾配降下法は勾配があって初めてw0→w1と動く事が出来ます。でも上のように真っ平らな所があったとしたら、勾配がゼロ、つまり先の式でw1=w0になってしまいます。こうなるともうこの重みは何度計算を繰り返しても全く値が変わらなくなってしまいます。右により良い場所があるのに、そこへたどり着くきっかけが無いのです。この状態にはまるとニューラルネットワークはちっとも賢くなってくれません。そう、これが「勾配消失問題」です。
ここでふと疑問。「うん、勾配が無くなるとそこで重みの推定が止まっちゃうのはわかった。んじゃ、そもそもそういう平坦な所が出ないような評価関数を使えばいいんじゃないの?」。真っ先にそう思いました。実際そういう評価関数を使えばうまく行きます。単純な単層ニューラルネットワークだったら。でも、層を重ねて多層にした時、真の問題が発生したんです。
② 多層化した時に表れる勾配消失問題
ディープラーニングではニューロンの層をいくつも重ねます。層を重ねると解ける問題が格段に増える事がわかったからです。所がいざ学習させてみると最初の方の層の学習速度がなぜか鈍い。理由が色々調べられ、最初の層に勾配消失問題が起きている事が判明しました。なぜそのような事になってしまうのか?鍵となるのは「連鎖律」というワードです。
連鎖律(Chain rule)は微分の性質の一つで、高校の数学で出てきた「合成関数の微分」の事です。ちょっと復習してみましょう。
〇 合成関数の微分
こういう関数f(x)があった時、この関数をxで微分した式(導関数)を求めます。これにはまずx^3をg(x)と置き換えます:
f(x)の中に別の関数g(x)が埋め込まれました(これが合成関数の由来です)。この時f(x)の導関数f'(x)が2つの導関数の積で表せる事が知られています:
実際2つの導関数を計算すると、
このように微分出来ました。
「関数の中に別の関数が入っている時に、その微分式は2つの導関数の積の形になる」。この微分の美しい掛け算の連鎖。ところが、これがニューラルネットワークでは逆に悪さしてしまったんです。
〇 連鎖律が悪さした
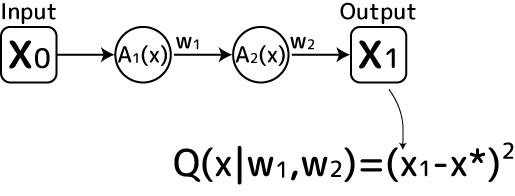
層が2つの超シンプルな多層ニューラルネットワークを例にしてみます:
入力刺激であるx0は最初の層に突入し、活性化関数A1(x)を通って何か違う値になります。それに重みw1が掛け算された新たな刺激が2層目に入力されます。2層目も同様にA2(x)活性化関数で別の刺激値となり、それにw2が掛け算され最終的な刺激値x1として出力されます。この出力刺激値x1がどれだけ良い感じかを評価するのが関数Q(x)です。上ではウルトラ単純化しているので、真の値x*との差の2乗値としてみました。
さて、ここまでの計算を実際の式で書いてみます。ちょっと式が沢山出てきますが、高校の微分の基礎知識があれば大丈夫なのでめげずに追ってみて下さい。まず最初の層の出力刺激値は、
と算出されます。この刺激xA1が次の層に入ります。同様にして次の層の出力は、
となりますよね。こうして最終出力x1が求まりました。さて、この試行はこれで良いとして、次の試行をするためにはw1とw2それぞれでのQ(w1)及びQ(w2)の勾配を求める必要があります。これは評価関数Q(x|w1,w2)をw1とw2それぞれで微分(偏微分)すればOKです。まずはw2で微分してみましょう:
評価関数Qにあるx1は関数になっていますから合成関数の微分が使えます。粛々と進めると下段のような割とシンプルな答えになりました。w2の勾配は誤差と活性化関数の値がそのまま反映されるようです。
では次にw1で微分した勾配式を求めます。求めたい導関数の式から眺めてみましょうか:
関数Qの中には直接w1が見えないのですが、それはx1の中に含まれています。そこでここでも合成関数の微分を使って2つの導関数の積の形にしています。右辺第1項はもうw1とは無縁となったのでおしまい。一方右辺第2項の導関数はw1でx1を微分する必要があります。x1の式中にw1は含まれている事はいるのですが、それはxA1の中に閉じ込められています。なので、ここもさらに合成関数の微分で積の形にしてしまいましょう:
便利ですよね、合成関数の微分(^-^)。この式を一つ上の式に代入すると結果としてこうなります:
この式を実際に展開してみると…、
こんな式になりました。真ん中の段でさらに合成関数の微分を使って展開しています。
さてこの第1層のw1での勾配の式。これ見よがしに強調した赤い部分に注目です。ここ、活性化関数の微分式になっていますよね。実はこれが勾配消失問題の原因だったんです!
③ 活性化関数の掛け算の連続が勾配を消失させていた
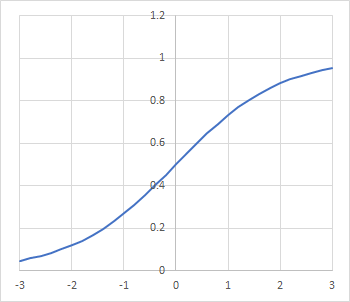
上の赤い部分、活性化関数の微分式ですが、勾配消失が問題になっていた時に活性化関数として良くシグモイド(sigmoid)が利用されていたそうです。シグモイド活性化関数は以下のような式で表されます:
この活性化関数は-∞~+∞の入力刺激値を0~1の範囲に収めてくれます。それ自体は有難い性質なのですが、問題はこの関数の微分式でした:
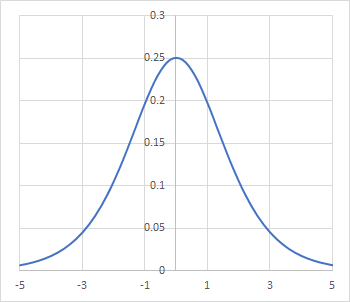
入力された刺激値に対し、最大でも0.25しか出力できません。しかも刺激が強くなるとあっという間に傾きがゼロに近付いてしまいます。という事は、先程の第1層の勾配を計算する式で赤く示した部分は勾配の値をかなり弱めてしまうんです。勾配の値が小さいと確率的勾配降下法はちょっとしか重みを変更できません。このため第1層は弱々しい学習しか出来なくなってしまうんです。しかも、これは層を重ねるたびに深刻になってきます。
層がもっと沢山ある場合、結果だけ示しますが第1層目の勾配は次のような式になります:
赤い部分の掛け算の連鎖、ギャーですよね。だってシグモイドを使いまくった場合、最大でも0.25です。それがn-1回掛け算されるんですから、指数関数的に勾配が減ってしまいます。
つまり、多層ニューラルネットワークでは、評価関数ではなくて各層に指定していた活性化関数によって勾配消失が生じていた、という事なんです。
④ 勾配消失問題を回避する活性化関数
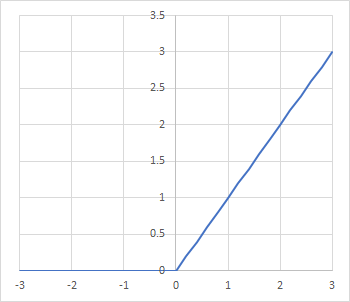
ここまで見てきた問題から、活性化関数の微分式の値が小さいと多層ニューラルネットワークの最初の方の層の学習が進まなくなりヤバイ、という事が分かりました。これを回避するためには、そういう事にならない活性化関数を考える必要がありました。そこで出てきたのが「ReLU(Rectified Linear Units)」です:
この活性化関数はマイナス値の場合は値を全部ゼロにして、プラスの場合のみ値をそのまんま出力します。この活性化関数、プラスの所の微分値は1です。という事は先ほどの赤い導関数の掛け算連鎖の所が全部1になります(プラスの場合)。つまりプラスの範囲では勾配消失問題が起こりません。そのためこの活性化関数は多層ニューラルネットワークで最も使用頻度の高いものになっています。しかし、マイナスの所は傾きがゼロになるため、刺激がマイナスの時に前の層の勾配に寄与しなくなってしまいます。そういうのを避けるため、ReLUをさらに改良した活性化関数が色々と考案されてきています。前章で紹介したELUやSELUなどはそういう改良版の一つです。マイナス値にも意味を持たせる事で勾配への寄与をある程度確保するようにしています。
という事で、この章では勾配消失問題について見てきました。自分で調べつつまとめる過程で、なぜ右上に伸びる活性化関数が多いのか、ようやく理由を掴めたような気がしました。ただ実は消失だけでなく「勾配爆発問題」というのもあります。消失の逆で勾配が凄まじい値に発散してしまい重み推定が崩壊してしまう現象です。活性化関数の微分式が1より大きい物が重なると、これもまた指数関数的に値が跳ね上がります。これにより爆発が起こるというからくりです。消失と爆発、そういう不安定さをどう解消したら良いのか?現在進行形で研究が続けられています。研究者の皆さんには頑張ってもらいたいですね(^-^)