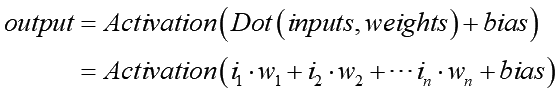VisualStudio + Pythonでディープラーニング
Denseを調べます
(2019. 12. 10)
ニューラルネットワークはニューロンが幾つか入った層(レイヤー)を連結する事で構成されます。Kerasには様々な層が用意されていますが、多分最も頻繁に使われるのが「Dense層(全結合層)」です。ここではそんな基本層であるDenseについてがっつり調べてみます。
① Denseとは?
Denseはlayers/core.py内で定義されているクラスです。ニューラルネットワークの層の形状のうち「全結合層」を表現出来ます。全結合層とはその層内の全てのニューロンが次の層の全ニューロンと接続する形態を言います:
実際の脳内のニューロンはこういう連結をしている訳ではありません。だってもしそうなら足だらけになっちゃうわけで(^-^;。ただ、次の層に対して各ニューロンが何らかの刺激を寄与する形を取れば、必要な所は太く、不必要な所は狭くする最適化を最大限に活用できます。
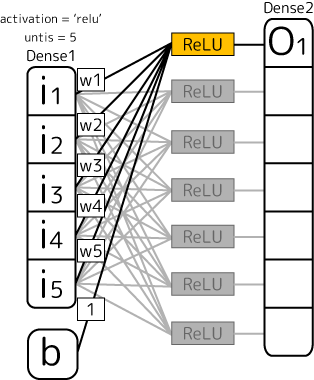
図から分かるように、Dense層を設定した場合、次の層の1ニューロンに対してすべてのニューロンが出力しています。出ているすべての足がシナプス回路の一つを表していて、すべてに重みwが存在しています。
② Dense作成時の引数
KerasではDenseクラスを生成する事でこの層の一つを表現できます。その定義を見てみましょう:
layers/core.py class Dense(Layer):
def __init__(self, units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs):
DenseはLayerクラスの派生クラスである事が分かります。生成時の引数はいーっぱいあります。今回はself以外のこの引数群を説明するのが目的です。では行ってみましょう。
〇 units(出力次元数)
その層から出力される次元数を正の整数値で指定します(必須)。ざっくり言えばニューロンの数と考えて良いです。例えば:
上のDense1層は次のDense2層の一つのニューロンに対して5本の出力をしています。なのでunits = 5です。5つのデータを出力するのでこの層は「5次元」となります。
〇 activation(活性化関数)
その層の出力刺激量を計算する関数を文字列で指定します。もしくは自作の関数を直接指定する事も出来ます。Kerasがデフォルトで持っている活性化関数は前の章でで紹介しましたのでご参照下さい。例えばソフトマックスを使いたい場合は、
dense1 = Dense( units = 5, activation = 'softmax' )
と文字列指定します。指定しなかった場合線形関数('linear')が設定されます。
活性化関数が実際にする計算は次のような式で表現されます:
前の層からの入力値ベクトルと1対1対応する重みベクトルとの内積を取る事で総合的な刺激量を一つ(スカラー)計算します。そこにバイアス値を加え、それを活性化関数の入力値として使用します:
図で表すとこんな感じの流れでしょうか。
〇 use_bias(バイアスを使用)
上の活性化関数の計算式にあるbiasを使うかどうかを真偽値(True、False)で指定します。デフォルトは「使用する(True)」です。バイアスは入力されてきた刺激に対して一定のオフセットをかけます。そして、この値もまた重みと同様にパラメータとして推定されます。バイアスは単純な数値なので活性化関数の微分値に影響を与えません(定数の微分はゼロなので)。よって、バイアスを使用しても勾配消失には影響しません。
バイアスを使用した場合と使用しない場合とで実際にステイパラメータ数は次のように変化します:
model.add( Dense( units = 1, activation='linear', use_bias=True ) )
model.summary()
___________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1) 2
=================================================================
Total params: 2
Trainable params: 2
Non-trainable params: 0
_________________________________________________________________
model.add( Dense( units = 1, activation='linear', use_bias=False ) )
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 1) 1
=================================================================
Total params: 1
Trainable params: 1
Non-trainable params: 0
_________________________________________________________________
上がバイアス項を使う場合、下が使わない場合です。モデル内のレイヤーの概要を出力させてみると(summary関数)、上の方が推定パラメータ数が2個(重みwとバイアスb)なのに対し、下は1個(重みwのみ)になっているのが分かります。
バイアスを使うと自由度が高まりますが、推定により多くの学習が必要になります。使わないとシンプルなモデルですがその分自由度が下がります。どちらが正解かは分からないのでテストで判断するしかないかなと思います。
〇 kernel_initializer(重みの初期化の方法)
学習を始める前の重みwを初期化する方法を指定します。パラメータであるwは最初の位置によって推定結果が変わります。よってより効率的に最適解に近付けるにはどういう初期値が良いか?というのはとても大切で、そして難しい問題なんです。
初期化方法は文字列か初期化用の関数を指定します。関数指定の場合、設定可能な関数はkeras.initializersモジュール(initializer.py)に定義されています。ここではざっと列挙します(詳細は別の章で!):
関数名 文字列 性質 keras.initializers.Zeros() zeros すべてをゼロに初期化 keras.initializers.Ones() ones すべてを1に初期化 keras.initializers.Constant( value=0 ) constant value定数値に初期化 keras.initializers.RandomNormal( mean=0.0, stddev=0.05, seed=None ) random_normal 平均mean、標準偏差stddevの正規分布で初期化 keras.initializers.RandomUniform( minval=-0.05, maxval=0.05, seed=None ) random_uniform 最小値minval、最大値maxvalの一様分布で初期化 keras.initializers.TruncatedNormal( mean=0.0, stddev=0.05, seed=None ) truncated_normal 平均mean、標準偏差stddevで-stddev~stdevの範囲の正規分布で初期化 keras.initializers.VarianceScale( scale=1.0, mode='fan_in', disribution='normal', seed=None ) VarianceScale 入力ユニット数や出力ユニット数で均された正規分布もしくは一様分布乱数で初期化(詳しくは後の章で!)
keras.initializers.Orthogonal( gain=1.0, seed=None ) orthogonal ユニットの重みベクトル(重みテンソル)が直交するように初期化(詳しくは後の章で!) keras.initializers.Identity( gain=1.0 ) identity ユニットの重みテンソルが2次正方行列の場合にそれを単位行列で初期化(詳しくは後の章で!) keras.initializers.glorot_normal( seed=None ) glorot_normal truncated_normalで平均を0、標準偏差をsqrt( 2 / ( <入力ユニット数> + <出力ユニット数> ) )としたのと同じ keras.initializers.glorot_uniform( seed=None) glorot_normal random_uniformでmin=-limit, max=limitとしたのと同じ。limit=sqrt( 6 / ( <入力ユニット数> + <出力ユニット数> ) ) keras.initializers.he_normal( seed=None ) he_normal truncated_normalで平均を0、標準偏差をsqrt( 2 / <入力ユニット数> )にしたのと同じ keras.initializers.lecun_normal( seed=None ) lecun_normal truncated_normalで平均を0、標準偏差をsqrt( 1 / <入力ユニット数> )にしたのと同じ keras.initializers.he_uniform( seed=None ) he_uniform random_uniformでmin=-limit, max=limitとしたのと同じ。limit=sqrt( 6 / ( <入力ユニット数> ) ) keras.initializers.lecun_uniform( seed=None ) lecun_uniform random_uniformでmin=-limit, max=limitとしたのと同じ。limit=sqrt( 3 / ( <入力ユニット数> ) )
指定しなかった場合のデフォルトはglorot_uniformです。
〇 bias_initializer(バイアスの初期化方法)
kernel_initializerと同様にバイアス値の初期化方法を指定します。指定できるのはkernel_initializerのと全く一緒です。
〇 kernel_regularizer(重みの正則化方法)
重みの正則化方法を指定します。デフォルトではNone(正則化無し)です。Kerasにデフォルトであるのは「L1正則化」「L2正則化」「L1L2正則化」という3種類で、keeras.regularizersモジュール(regularizers.py)に定義されています:
方法 意味 keras.regularizers.l1( l1 ) L1正則化。推定パラメータの絶対値を評価値に加算 keras.regularizers.l2( l2 ) L2正則化。推定パラメータのべき乗値を評価値に加算 keras.regularizers.l1l2( l1, l2 ) L1,L2正則化の両方を加算
この「正則化」とは情報量に基づく考え方で過学習(overfitting)を回避する一つの方法です。例えば同じデータに対してパラメータ数が非常に多いと、そのデータの形により沿ったフィッティングになります。この場合、そのデータセットの再現力は高いのですが、新しいデータに対して弱くなてしまう事があります(いわゆる過学習です)。かといって少なすぎるパラメータだとそもそも曖昧なモデルになってしまい、これも良いモデルとは言えません。では「どの位のパラメータ数でフィッティングするのが程良いのか?」これを図る方法としてこの正則化が使われます。
評価値が同じだとしたら、パラメータ(推定された重み)の合計値が小さい程極端な偏りが少ないより良いモデルである、という考え方です。L1正則化の場合はパラメータの値の絶対値を評価値に加算する事でそれをペナルティーとしています。一方でL2正則化はパラメータ値のべき乗値を加算します。上の関数の引数はその絶対値や加算値に掛け算されるスケールで、値が大きい程ペナルティーの寄与が大きくなります。
〇 bias_regularizer(バイアスの正規化方法)
kernel_regularizerと同様にバイアスの正規化方法を指定します。指定できるのは上と同じで、正則計算時にバイアスの値が使用されます。
〇 activity_regularizer(レイヤー出力の正規化方法)
そのレイヤーの出力値に対して正則化をかけます。指定できるのは上と同じです。レイヤーの出力値が正則計算に使用されます。特定のレイヤーが過度に大きな値になるのを防ぐ事が出来ます。
〇 kernel_constraint(重み制約関数の指定)
推定される重みに対して制約条件を付記できます。デフォルトはNone(制約しない)です。次の関数が指定できます:
方法 意味 keras.constraints.max_norm( max_value=2, axis=0 ) max_valueに指定した値以下になるようにする。axisは重みベクトルのどの成分を対象にするか配列で指定する。 keras.constraints.non_neg() 0以上の値になるようにする keras.constraints.uni_norm( axis=0 ) 推定値ベクトルの長さが1になるように正規化する keras.constraints.min_max_norm( min_value=0.0, max_value=1.0, rate=1.0, axis=0 ) min_value~max_valueの間になるようにする。rateは1で厳格にその範囲に、1未満はその範囲をやや外れても良くする
param = ( 1 - rate ) * param + rate * clamp( min_value, max_value )
例えば重みがマイナスになる事があり得ない状況などではnon_negを指定するなど明確な制約がある場合に使えます。
〇 bias_constraint(バイアスの制約関数の指定)
kernel_constraintと同様にバイアスの推定値に制約をかけます。指定できるのは上と同じです。
③ 入力層のinput_shape設定
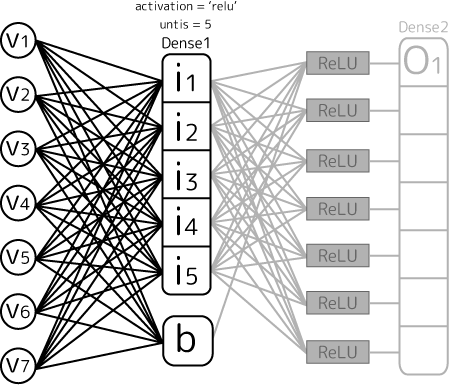
一番最初の層に限り、入力データがどういうデータの型になっているかinput_shapeで指定する必要があります。例えば次のように設定した場合、
model = Sequential()
model.add( Dense( units = 5, activation='relu', use_bias=True, input_shape=( 7, ) ) )
次のような入力層が作成されます:
このv1~v7が1セットとなってパラメータ推定に使われる事になります。
④ 各種取得関数
Denseクラスには設定したモデルの構成を見たり、推定された重みがどうなっているのかを調べるなど、そのレイヤーの中身を知るための関数が幾つか定義されています。Kerasは取得関数は「get_*****()」という命名規則で統一されているようなので、確認できたものを以下に列挙します。
〇 get_weights()
推定された重みを取得します。
dence1 = Dense( units = 1, activation='relu', use_bias=True )
...<学習>
print( dence1.get_weights() )
学習後次のように出力されます:
[
array([[0.49840432]], dtype=float32),
array([0.02041926], dtype=float32)
]
最初のarrayが重みwの推定値です。重みの数だけ数値が出てきます。dtypeは推定値の型でfloat32で出力されているようです。2番目のarrayはバイアスの推定値です。もしバイアスを使わなければこの項は出力されません。
〇 get_config()
層の設定項目を辞書形式で列挙してくれます。printすると以下のような項目が出力されます(スペース、改行で整理しています):
{
'name' : 'dense_1',
'trainable' : True,
'dtype' : 'float32',
'units' : 1,
'activation': 'linear',
'use_bias' : True,
'kernel_initializer': {
'class_name': 'VarianceScaling',
'config' : {
'scale' : 1.0,
'mode' : 'fan_avg',
'distribution': 'uniform',
'seed' : None
}
},
'bias_initializer': {
'class_name': 'Zeros',
'config' : {}
},
'kernel_regularizer': None,
'bias_regularizer' : None,
'activity_regularizer': None,
'kernel_constraint' : None,
'bias_constraint' : None
}
これはこの章で説明してきたものそのものですよね(先に引数の説明しておいて良かった(^-^;)。このprint出力はJSONでそのまま読み込めますので外部化も楽です。
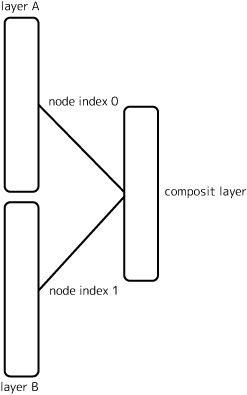
〇 get_input_at( node_index )
その層にnode_index番目のノードに入力されてくるデータの型を調べる事が出来ます:
dence1.get_input_at( 0 )
出力は次のようになります:
Tensor("dense_1_input:0", shape=(None, 1), dtype=float32)
Tensorというのは「テンソル」という数学的な型の事です(詳しくはいずれ)。dense_1_inputは入力ノード番号、shapeは入力されるデータの形式で、最後の数字(1)が次元数になります。dtypeはデータの型です。
「ノード」というのはその層に入力される層に割り振られた番号の事です。Sequenceモデルだと単純連結なのでノード番号は常にゼロですが、複数の層の情報を統合する層などではこの番号が0,1,2,...と増えていきます。
〇 get_input_mask_at( node_index )
指定のノード番号に紐づいた前層に入力マスクがある場合、その情報を取得します:
dence1.get_input_mask_at( 0 )
有効な入力マスクが設定されている場合次のような出力を得られます:
Tensor("masking_1/Any_1:0", shape=(None,), dtype=bool)
もし入力マスクが無ければNoneが返ります。
マスクというのは特定のデータ処理を飛ばす事を指し、keras.layers.Maskingで設定する事が出来ます。例えば欠損データや外れ値などを処理したくない場合にMaskingを使います。
〇 get_input_shape_at( node_index )
指定のノード番号に紐づいた層から入力されてくるデータの形式を取得します。次のような出力を得られます:
(None, 5)
最後の数字は入力次元数です。上の出力例だとnode_index番の層から5次元のデータが入力されてくる、と読めます。
〇 get_output_at( node_index )
出力ノード番号に対して出力される情報を返します:
Tensor("dense_1/BiasAdd:0", shape=(None, 5), dtype=float32)
一つの層から複数の層へ分配出力される場合出力ノード番号が0,1,2,...と割り振られます。
〇 get_output_mask_at( node_index )
指定のノード番号にマスク出力がある場合その情報を返します:
Tensor("masking_1/Any_1:0", shape=(None,), dtype=bool)
前の層のどこかでマスキング層があると有効な値が返ります。
〇 get_output_shape_a( node_index )
指定のノード番号に紐づいた層への出力形式を取得します:
(None, 5)
最後の数字が次元数です。
〇 get_updates_for( inputs )
〇 get_losses_for( inputs )
ゴメンなさい、良く分かりませんでした…(-_-;。知っている方Twitterなりメールなりで教えて下さい。
という事でDenseレイヤーについて色々調べてみました。Kerasには他にも様々なレイヤーが用意されていて、また独自のレイヤーも作る事が出来ます。この辺りは折を見て(僕がもっとレベルアップした時にw)説明できたらと思います。