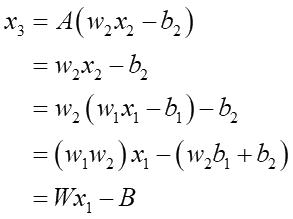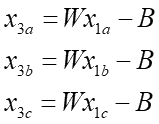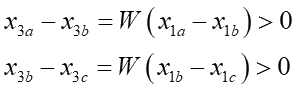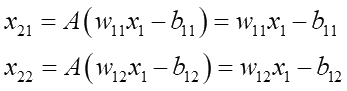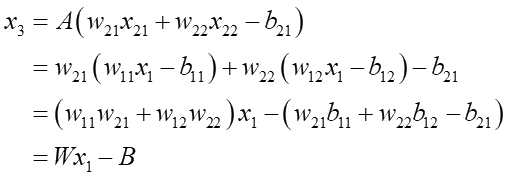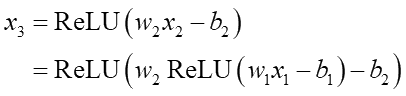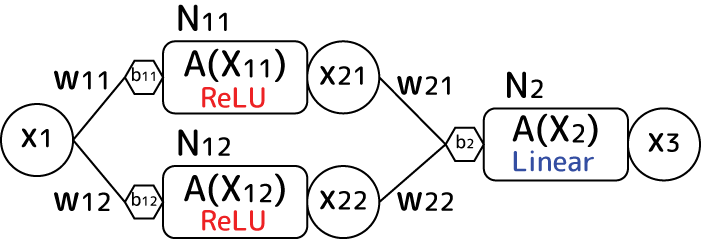VisualStudio + Pythonでディープラーニング
非線形な活性関数がもたらす恩恵
(2019. 12. 17)
「Kerasの活性化関数を知ろう」で色々な活性化関数を見てきました。一通りグラフも示しましたので入力される値に対してどういう反応を示すかイメージもできるかなと思います。所で、その活性化関数はlinear以外は曲線だったり折れ曲がったりしていました。そういう線形以外の関数(不連続のも含む)の事を「非線形関数」と言います。真っすぐじゃないから非まっすぐ、という事です。これら活性化関数の形を見ていると色々と疑問が湧いてきます:
そこでニューラルネットワークに非線形活性化関数を使うとどういう恩恵が生じるのかを考えてみたいと思います。
① 活性化関数の使われ方
まずはニューラルネットワークでの活性化関数の使われ方をおさらいしましょう。
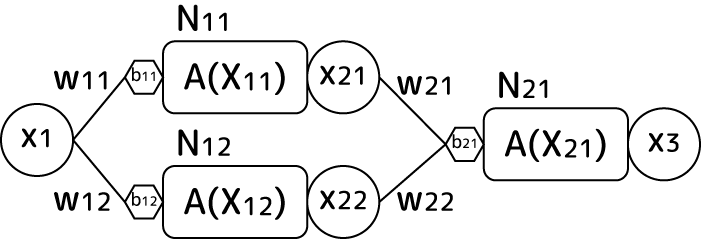
ある層内のニューロンに入力されるデータx1,x2,...があるとします。これらにはまず重みwが一つずつ掛け算されます。入力値が8個あるなら、重みも8個です。さらにその入力値にオフセットをかけるバイアスbが一つのニューロンに付き一つ設けられています。ここまでを図示するとこんな感じです:
入力された値は重みが掛け算された後に上の式のように全部足されます。またバイアスは引き算されます(バイアスが閾値であるため)。こうして全入力値は一つの「刺激値」として活性化関数に渡されます。レイヤー内にニューロンが複数ある場合、各ニューロンごとに上の重みセットとバイアスが設けられます。ただ活性化関数については通常同じ物が使われます。
活性化関数の結果はこの層の一つの出力値になります。ですからニューロンがm個ある層からは値がm個出力されるわけです。そのm個の値が次の層の入力値になります。これが連なるのがニューラルネットワークです。ここから、同じ入力値、同じ重み、同じバイアスであったとしても活性化関数が異なると層からの出力値セットが変わってくるのがわかりますね。
② 線形活性化関数の限界
活性化関数に線形関数(linear)を用いた場合、A(X)=Xなので上の刺激値X1がそのままそのニューロンの出力値となります。そしてそれは次の層の入力値の一つにもなります。では下図のような単純な例で、最初の刺激値x1がlinear2層を通るとどういう値になるか式を展開して見てみましょう:
まずx2の値は次の通り:
これが2層目の入力値になるので、次のように展開されます:
最終値のx3は右辺最下段のように傾きW、切片-Bの線形の式に初期値x1を突っ込むと求まる事が分かりました。傾きWは重みw1とw2の掛け算になっているので、重みの符号によってプラスにもマイナスにもなりますが、ここで重要なのは上の式では初期値の並びと最終値の並びが変わらないという事です。例えば初期値としてx1a>x1b>x1cという3つの値を個別に入れたとすると、最終値x3a,x3b,x3cは、
となります。最終値の大小関係は、もしWがプラスならば、
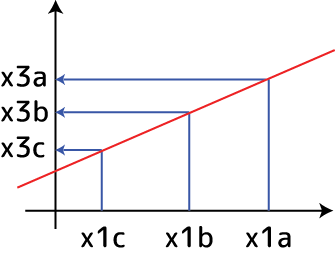
ここからx3a>x3b>x3cが言えます。Wがマイナスならこの並びは逆になります。つまり活性化関数に線形関数のみを用いた場合、最初の入力値は変化こそしますが、最終値はそれを単純に別の線分に写像した物にしかならない事がわかります:
これだとわざわざ多層化する意味がありません。
ではニューロンが2つの場合はどうでしょうか?
第1層の出力値x21とx22はそれぞれ、
これらが第2層の入力値になって合成されると:
んー、やっぱり初期値を用いた線形関数に収束してしまいます。ニューロンを複数にしてもあまり大きな意味を持たないんですねぇ…。
つまり、活性化関数に線形関数のみを用いた場合、層を多層にしても、ニューロンをたくさん並べても、入力値を線形に変換しただけの結果になってしまいます。それは単層と変わらないのです。この事から、実は線形関数はニューラルネットで普通用いられません。
③ 非線形活性化関数に差し替える
②で面白くなかったのは、x1a>x1b>x1cという並びが線形に変換されるため、その順番も大きさの差の比率も変わらないという点でした。そのせいで多層化する意味が全然無くなってしまいます。そこで活性化関数を非線形な物に変えてみます:
ReLU(Rectified Linear Unit)は入力値がゼロ以下はすべてゼロ、ゼロ以上は線形関数と一緒というシンプルな非線形活性化関数です。これで②と同様に最終出力のx3がどうなるのか式で展開してみます。まずx2は、
となります。x2の値がどうなるかは括弧内の符号によりますが、これ結構複雑なのが分かりますよね。例えばx1がマイナス値だとしても切片であるbが大きくマイナスなら結果としてプラスになるかもしれません。w1がマイナスならx1がマイナスでも掛け算の結果はプラスになりますが、それがb1よりも小さければx2はゼロになってしまいます。元の入力値の大きさ、重みwの符号、bの大きさや符号によって結果に変化が出るという事です。ReLUの重要な性質として、w1x1という入力からの刺激がbを越えたら初めて刺激として作用し始める様子から分かるように、ReLUではバイアスbが刺激の「閾値」として働いている事が分かります。入力刺激×重みがバイアスを上回った時に初めて刺激としてニューロンが活性化する。ReLUは正に活性化関数という名前の仕事をしている訳です。ここが線形関数と大きく違う点です。
このx2が入力値として2層目に差し込まれます:
これは中々に複雑です。x3の結果をグラフで例示してみると、こんな感じになります:
第1層でx1cはマイナス値だったため(重みとバイアスは無かったとして)出力はゼロです。x1bとx1aは正の値なのでそのまま第2層の入力値になります。第2層では重みw2とバイアスb2により各入力値はスケールとオフセットがかかるため、上の図では正だったx1bがマイナスに落ち込み、結果としてゼロに落ち着いています。結果としてx3aのみが有効な出力として採用されています。
ReLUを使うとこのように、紆余曲折を経て最終的にマイナスになった値はことごとくゼロに、それ以外は有効値になる、という「2値的な解釈」がより鮮明になります。非線形な関数を使うと線形には無い出力の変化を得られる訳です。ただし、この1変数1ニューロンの超単純な層では、値の2値的解釈まではできますが「入力値の順序の入れ替え」までには至りません。
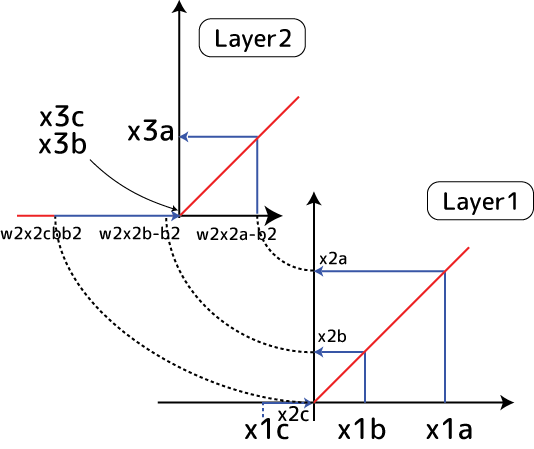
④ ReLU+ニューロンが2つ以上になった時に順序の逆転が可能になる!
ReLU+1ニューロンの場合、入力値は最終的にゼロに落ち込むか有効な値を取るかの2値的解釈になりました。ではニューロンが2つ以上になった場合はどうなるでしょうか?実はこの時に初めて「順序の逆転」が起こります:
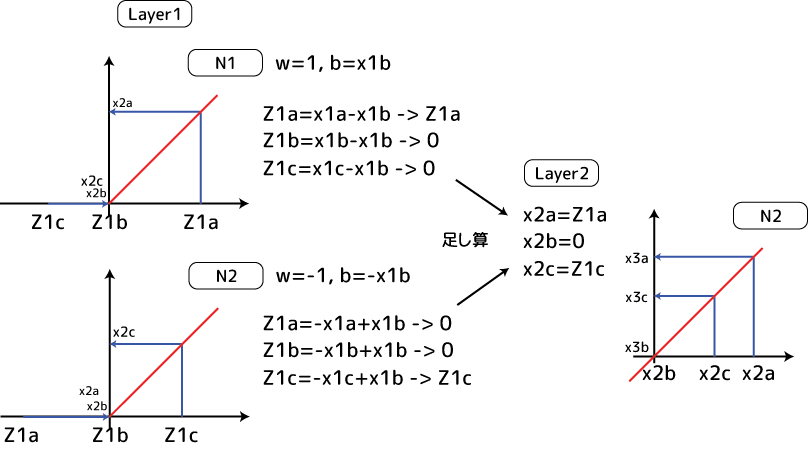
ちょっと情報量が多いのですが下の図をご覧ください:
入力値は1つです。今x1a>x1b>x1cという大小関係の入力値があるとします。第1層にある2つのニューロンにこの入力値が入ってきます。左上のニューロン1の重みwが1、そしてバイアスがx1bだとします。すると活性化関数にはグラフの横軸のような順序の変数が入ります。その結果Z1aという値のみが有効になりました。一方ニューロン2は重みが-1、バイアスが-x1bとニューロン1と真逆になっているとします。するとグラフにあるようにZ1cだけがプラス値と有効値になります。
これら2つのニューロンの値は次の第2層の入力値として入ってきます。レイヤー2の活性化関数に入る前に、これらの値は足し算されます(重みとの掛け算も発生しますが上では1としています。バイアスは0)。その足した結果はx2a>x2c>x2bと初期値の順序と異なっています!!これ、物凄い重要な事なんです。
⑤ 入力と出力の順序入れ替えは「非線形分離」
活性化関数として線形関数のみを用いた場合、入力の値の大小に対して出力の大小順番は同じになってしまいました。一方ReLU+2ニューロンを用いた時には各ニューロンの重みとバイアスによっては大小順番の一部が入れ替わる事があるのが分かりました。これは線形関数では起こりません。
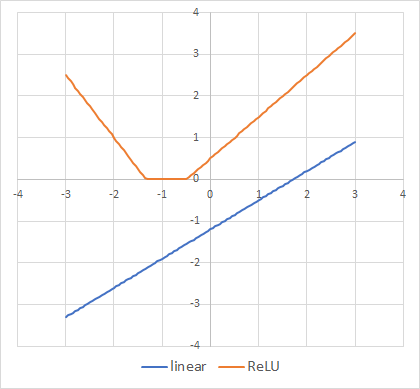
linearとReLU双方について、入力刺激量と最終的な出力の関係をグラフでイメージすると次のようになります:
ReLUのグラフは実際に1入力値2ニューロンの層から出力された物を足し合わせて最終出力としたものです(Layer1[
N1: w=1, b=-0.5 N2: w=-1.5, b=2 ], Layer2: linear)。線形側が入力値に対し単調増加なのに対し、ReLU側は下に凸の折れ線になっています。勿論ReLUのグラフは各ニューロンの重みやバイアスで形が色々と変わります。線形にもなるでしょうし、上に凸の折れ線にもなれます。この「凸の形になれる」というのが重要です。
例えば最終出力が1以上の物がA、それ以下をBというカテゴリーに分類するとした時、線形側は入力値が3以上辺りでA、3以下がBと完全分離されます。このように入力値のある1点で出力を完全に2つに分ける事が出来る物を「線形分離可能」と言います。linearは線形分離可能な問題を解く事が可能です。
一方ReLUの方は1以上の所がマイナス側とプラス側の2箇所に存在しています。これは1点での完全分離にはなっていません。このように複数の点で分離される物を「非線形分離」と言います。非線形分離な物は線形で分離する事は出来ません。
実際の世の中の現象では例えば「入力値が3以下と7以上が有効」という有効範囲が2箇所以上に分離している、分けるのに非線形分離が必要な状態がいくらでもあります。そいう分離をReLUのような非線形な活性化関数と複数ニューロンのセットが可能にしているというのが大変に重要です。この発見がニューラルネットワーク活用の一つの起爆剤になりました。
⑥ 2つ以上の入力に対するXOR問題も解決へ
ReLU+複数ニューロンで非線形な分離ができる。この性質は「XOR問題」も解決しました。XORというのは「排他的論理和」と呼ばれている、足し算や掛け算と同様に2つの値で行われる演算(2項演算)です。ただし演算に使われる値は0と1のみで、以下のルールに従います:
入力A 入力B 出力 0 0 0 1 0 1 0 1 1 1 1 0
AとBが同じ値の時にはゼロ、双方が異なる時に1になります。この「双方異なる」というのが排他的という名前の由来です。これが実は「非線形分離問題」になっています。模式的なグラフで示してみましょう:
2つの入力値に対して出力は上図のように配置されます。これを分離して同じ値同士でまとめようと思っても、直線一つではどう頑張っても分離出来ません。もし1本の直線だけで分離できるのなら線形分離可能問題なのですが、排他的論理和は非線形分離問題なんです。ですからlinearではXOR問題は解けません。しかし活性化関数にReLUなどの非線形関数を用いると⑤で示したように非線形分離が出来るので、XOR問題も解く事が出来ます。これが実際に解けるかは、次の章で実験してみたいと思います。
⑦ 世の中は非線形分離のカオス状態なので
ここまで活性化関数に非線形関数を用いると非線形な分離が出来るようになる事を示してきました。でも、そもそも非線形分離がなぜ重要なのでしょうか?これは世の中を眺めると良く分かります。
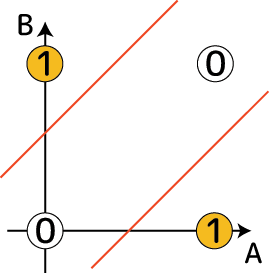
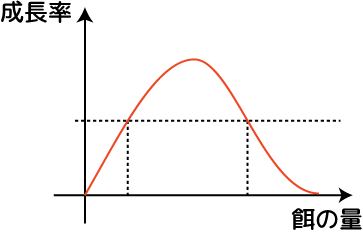
例えば水槽で飼っている魚が「餌をあげると大きくなる」という単純な関係だと考えてしまったら、魚を大きくしたい養殖業の人達は溢れる程の餌を水槽に放り込むでしょう。でも、実際それをしたらどうなるか?水槽の中の環境が悪化して、魚は病気になってかえってうまく成長してくれなくなるでしょう。という事は、魚をあるサイズ以上に成長させる餌の量には適正範囲量があるという事になります。これは非線形分離です:
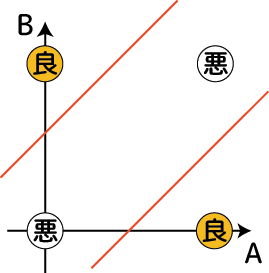
薬には「飲み合わせ問題」があります。薬Aはある病気に良く効く、薬Bは別の病気に効くとします。ではAとBを一緒に服用したらさらに良いかというとそうならない事もあります。薬AとBに含まれる成分が作用し合い、思いもよらない副作用が起こる事があるからです。よってこの薬の飲み合わせは⑥で出てきたXOR問題になっています。ですから非線形分離です:
1つや2つの要因でも起こりうる非線形分離状態。では要因が何百、何千もあるものだとどうでしょう。それらが線形分離できる事はまず無いでしょう。でもそれら複雑に干渉し合う要因から出てくる出力を上手に分離できる手法が欲しい。なのでモデルが非線形分離出来るポテンシャルを持つというのが物凄く物凄く重要になるんです。
という事で、この章では非線形な活性化関数を用いる事による恩恵について考えてみました。