ホーム < ゲームつくろー! < C++踏み込み編 < charとUnicodeとワイド文字をごっちゃにしないために
その4 charとUnicodeとワイド文字をごっちゃにしないために
Visual Studio 2003あたりになってから、ちらほらと出てきたのが「Unicode」や「ワイド文字」という言葉。DirectXでもたびたびこれに苦しめられたりします。どうも世の中従来の1バイト文字からUnicodeへ過渡しそうな気配です。これらの文字の仕様については色々なサイトや辞書に詳しく説明されています。しかし、しっかりまとめないとやっぱり混乱してしまうもんなんです。「バイト文字をUnicodeに変換するのと、マルチバイト文字をワイド文字に変換するのは何が違うのか?」と聞かれたときに、すっと回答できますでしょうか?できる方はすばらしい。迷った方も大丈夫。世の中そんなもんです。
ここでは、charとかUnicodeとかワイド文字が頭の中でごっちゃになっている方のために、これら文字コードについて整理し、プログラム上ですっきり扱うための方法をご紹介します。
① 文字セットと文字コード、ごちゃごちゃになっていませんか?
文字コード関係に触れていつも思うのは、その言葉の言い回し。これ、やられるんですよ。シングルバイト文字、ダブルバイト文字、マルチバイト文字、ワイド文字、ASCII、Unicode、UCS-2、UCS-4、Shift-JIS、etc...。これら言い回しが乱立するもんですから大混乱してしまうんです。まずはこれらの言葉の関係を整理しましょう。
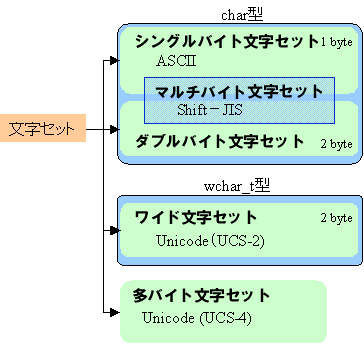
言葉の言い方として「文字セット」と「文字コード」があります。文字セットというのは同じ体系を持つ文字コードの集まりです。文字コードというのは、何らかの規格化された文字の表し方です。これを念頭に入れて以下をお読み下さい。
シングルバイト文字セット(Single Byte Character Sets : SBCS)は8ビットつまり1バイトで表現される文字全てを指します。ASCII文字は純粋に1バイトなのでシングルバイト文字セットに含まれます。Shift-JISの先導バイトが無い文字もここに含まれます。
ダブルバイト文字セット(Double Byte Character Sest : DBCS)はその名の通り2バイトで表現される文字を指します。C言語では、シングルバイト文字もダブルバイト文字もchar型の配列として扱えます。Shift-JISで先導バイトがある文字はここです。
紛らわしくて混乱するのがマルチバイト文字セット(Multi-Byte Charcter Sets : MBCS)。これは「多バイト文字」と表現されて「2バイト以上の文字」を指すこともありますが、MSDNの規定では「1バイトおよび2バイト文字」となっています。どうもこれは世の中とMicrosoftの間で定義の相違があるようです。MSDNに従えば、シングルバイト文字もダブルバイト文字もマルチバイト文字に含まれると言うことになります。Shift-JISはここに含まれます。
ワイド文字セット(Wide Character Sets)は、常に16ビット長(2バイト)を持つ文字とされています。定義上からはワイド文字もダブルバイト文字も同じなのですが、言語上からは別物と区別されていまして、ワイド文字はchar型で扱うことができません。ワイド文字を扱うにはwchar_t型を用います。この文字コードに含まれるのがUnicodeです。ただUnicodeには4バイトまで拡張されたUCS-4というのがありますが、これがワイド文字に含まれるかどうかは調べがつきませんでした。
ASCII文字コード(American Standard Code for Information Interchange)は、シングルバイト文字セット、つまり1バイト文字です。0x00-0x7fまでの128文字(7ビット分)は規格上対応する文字が固定されていますが、0x80-0xffまでの残り128文字は拡張領域と言って各国で汎用規格を定めて良い事になっています。
Unicode(ユニコード)は1993年にISOの1つとして定められた文字コード規格で、当初は2バイト文字で世界中の文字を表そうとしたのですが、ちょっと多言語国家から批判が起こり、現在は4バイト文字まで対応するようにしています。規格当初の2バイト文字はUCS-2、4バイトまで拡張したものはUCS-4と呼ばれています。プログラム上でUnicodeはワイド文字として扱われています。
Shift-JISコードは日本語を扱うための文字コードの1つです。1バイト及び2バイト長の文字を持ちマルチバイト文字セットに分類されます。2バイト文字の場合1バイト目が「先導バイト」という特殊なコードになっており、この有無で1バイト文字か2バイト文字かが区別されます。
(その他にも多くの文字コードがありますが、その詳細はIT用語辞典e-Words(http://e-words.jp/p/c-format-character-code.html)をご覧下さい。)
今回挙げた文字コードを体系的にまとめると次のようになります。
これを見ると、プログラム(Visual C++)の視点からは、マルチバイト文字を扱えるchar型と、ワイド文字を扱えるwchar_t型に大別されることがわかると思います。よって以下からはこの2種類を区別して説明します。
② リテラル文字の扱い
C言語で文字列というと本来はシングルバイト文字セットのことで、それは次のように代入できる仕様になっていました。
const char* str = "This is ASCII code that is one of Single Byte Character Sets.";
このダブルクォーテーションで囲まれた文字列のことを「リテラル文字」と言います。ASCII文字のみで構成される場合、これは全く問題ない代入です。マルチバイト文字(Shift-JIS)はシングルバイト文字の並びを利用したものなので、char型として扱えます。よって以下のような代入はOKです。
const char* str = "これらは全部マルチバイト文字(SHIFT-JIS)です。";
さて、UnicodeはMSDNによると「ワイド文字」のくくりになっています。UnicodeはShift-JISのように先導バイトを持たないまったく別体系の2バイト文字コードです。Unicodeのようなワイド文字は、char型ではなくてwchar_t型としてマルチバイト文字と区別されます。ですから、次のような代入はできません。
const wchar_t* str = "この代入はできないのですよ";
実際にこれをコンパイルすると次のようなコンパイルエラーが出てしまいます。
コンパイルエラー error C2440: '初期化中' : 'const char [27]' から 'const wchar_t *' に変換できません。
明示的にキャストしても実はだめです。
const wchar_t* str = (wchar_t*)"この代入もやっぱりできないのですよ";
こうするとコンパイラは通りますが、代入される文字がそもそもASCII及びShit-JISコードなので、苦笑する文字列が代入されてしまいます。
では、上のような代入を成立させるにはどうしたら良いか?これは右辺がワイド文字列であればよいわけです。実はそのための書き方がちゃんと用意されています。
const wchar_t* str = L"この代入はOKです";
「L」という接頭子(プレフィックス)がダブルクォーテーションの前に付きました。これを「Lプレフィックス」と言います。このおまじないのような書き方により、右辺のリテラル文字はワイド文字として扱われます。当然この代入は正常で、コンパイルエラーは無くなります。
しかし、Unicodeの場合にLを付けて、そうでない場合にLをはずすとなると、これはこれで面倒なものです。マルチバイト文字でもUnicodeでも、コードを変えずに使用したいと思うのがプログラマーの性です。そこで、もう少し便利な接頭子が用意されました。それが「_T汎用テキストデータ型(マクロ)」及び「_TCHAR汎用テキストデータ型」です。これは、Microsoft固有の仕様ですが、マルチバイト文字、ワイド文字(Unicode)のどれが来ても大丈夫なようにリテラルをコンパイラの設定に合わせて対応させます。
const _TCHAR* str = _T("この代入はマルチに対応できます");
このマクロがうまく動く仕組みは至って簡単です。どこかで_UNICODEというマクロ定数が設定されていたら、コンパイラがUnicodeモードであるとして_TCHARをwchar_t型に置き換えます。_UNICODEが設定されていなければ、通常のchar型に置き換えるというわけです。_Tも、Unicodeモードの場合はLプレフィックスに化け、そうでないときは何も影響しない空白となります。裏での動きはどうあれ、今後のプログラムで文字列は上のような汎用型で定義しておいた方が幸せになれるかもしれません。尚、_TCHAR型及び_Tマクロは「tchar.h」という汎用ヘッダー内で定義されていますので、使用する時にはこれをインクルードする必要があります。
③ 汎用書式付き文字列関数
リテラルは固定した文字列定数ですが、時に文字列を実行時に生成することがあります。そういういわゆる「書式付き文字列」は、その昔はsprintf関数を使って作成していましたが、今この関数を使うとコンパイラが次のように文句を言ってきます:
コンパイル警告 warning C4996: 'sprintf' が古い形式として宣言されました。
1> c:\app\vs2005\vc\include\stdio.h(345) : 'sprintf' の宣言を確認してください。
1> メッセージ: 'This function or variable may be unsafe. Consider using sprintf_s instead. To disable deprecation, use _CRT_SECURE_NO_DEPRECATE. See online help for details.'
英語部分を訳しますと
「この関数もしくは変数は安全ではない。sprintf_s関数の使用を考えなさい。これを無効にするには、_CRT_SECURE_NO_DEPRECATE.を使うこと。詳細はオンラインヘルプを参照」
となります。これは、sprintf関数自体が安全性を欠く古い関数であるがゆえに警告されているわけです。代わりに使えと言われたsprintf_s関数を使うと、より安全に書式付き文字列を生成できます。この関数についてはMSDNのオンラインヘルプに使用方法が掲載されています。
書式付きワイド文字を生成する場合もswprintf関数という似たような関数を用いますが、これも同様に警告されます。
両方に対応するような汎用的な書式付き文字列生成関数というのも実はあります。それは、_stprintf関数です。これは、_TCHAR型を扱う関数になっています。_TCHAR型は_UNICODEフラグによってchar型にもwchar_t型にもなると説明しました。その機能を丸々活用してくれるというわけです。使用例を以下に挙げます。
TCHAR str[50];
_stprintf( str, _T("今日の玉ねぎの値段は%d円です。"), 138 );
_Tマクロを使うのがポイントですね。ただ、実はこの関数も警告を出されてしまいます。
警告を出さないためには、新しく出来たセキュリティー強化版汎用書式付き文字列関数である_stprintf_s関数を用います。これで完璧です。
TCHAR str[50];
_stprintf_s( str, 50、_T("今日の玉ねぎの値段は%d円です。"), 138 );
第2引数にバッファサイズを指定しなければいけなくなりました。これは納得です。これで、文字コードによって異なるわずらわしい文字列の生成からすっきりと解放されます。
④ 文字列変換
適切な型とマクロを使用することで、プログラムの汎用性を高める事はできたものの、やはり時に文字列を別の文字コードに変換しなければならない状況が生じます。例えば標準テンプレートライブラリのstringは後発であるワイド文字との互換性がありません。よって、stringを使う時にはワイド文字をマルチバイト文字に変換する必要が出てくるわけです。Direct3Dでフォントを作成する時や、DirectShowでファイル名を指定する時には、ワイド文字を要求されます。つまり、マルチバイト文字をワイド文字に変換する方法も必要になります。
双方の変換関数は以下の通りです。
元の文字 変換先の文字 ワイド(Unicode) マルチバイト文字 -> ワイド文字(Unicode) MultiByteToWideChar ワイド文字(Unicode) -> マルチバイト文字 wctomb
WideCharToMultiByte
双方共にWindows API関数であるMultiByteToWideChar関数及びWideCharToMultiByte関数で対処できます。wctombはCランタイムライブラリです。
今後、プログラム上での文字列はUnicodeに統一される感じがします。世界中の文字に対応できて文字カウントも楽となれば当然です。しかし、C言語は今後も相当長い間使われることになりますので、両方の文字体系に対応できるプログラムを知っておくことが大切ですね。