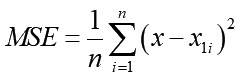VisualStudio + Pythonでディープラーニング
ミニマムでディープじゃないラーニングから始めよう
(2019. 12. 3)
「Kerasの使い方をざっくりと」でざざっと見てきたように、Kerasを使うとディープラーニングのモデルを色々と組めます。KerasやそのベースであるTensorFlowがバージョンアップすると、最新論文に掲載されているようなモデルもすぐに使えるようになります。でも正直な所、僕を含む初学者にとってその域はまだまだ神領域。僕らの頭には「そもそもどういうモデルを使ったらいいの?」「どういう関数使ったらいいの?」「ごめん、モデルって何?」「データどうやって揃えるのさ?」などなど、地べたを這うような疑問ばっかりが浮かぶ毎日です。分からない事祭りでえ、まるで周囲を防壁でガッチリ囲った要塞のように突破口が見いだせないのが今の僕のディープラーニングに感じる印象です。とは言え、何か取っ掛かりを掴まないと先に進めないのも確か。んじゃ、地道ではあるけども、ちゃんと地に足を付けて土台を積み重ねていこう。土台が高くなれば、壁は越えやすくなるんです。
そこで、ここではKerasを用いてミニマムでディープじゃないラーニングをやってみようと思います。
① 最低限のニューロン
ディープラーニングで使われているニューラルネットワーク(NN)とは人などの脳にある「ニューロン」の連携の仕組みの事です。ニューロンというのは脳細胞の一つで、軸索という足を互いに連結して微弱電流を伝える事で記憶や情報伝達を担います(実際は軸索の先で化学反応が起こる事で伝達が完了します)。ニューロンがどうして物を記憶し一連の処理を可能にしているのか、今の所完全には解明されていないのですが、どうやらニューロンを沢山束ねて繋ぎ合わせると「記憶」と「処理」が出来るらしい…、そういう事は分かっています:
ニューロンは自分の中に入ってきた電気刺激を「一端解釈」し、その結果となる新たな刺激を自分の足(軸索)の先に接続した別のニューロンに伝えます。この時太い軸索である程刺激はより強く伝わります。入力された刺激をいったん変換し軸索の太さに比例した強さで次のニューロンを刺激する。これは次のような関数で表現できる事になります:
xが入力される刺激の大きさ、w1が軸索の太さに相当する係数(重み:Weight)です。A(x)は入力された刺激を解釈する部分で「活性化関数」と呼ばれています。もし入力された刺激をそのまま伝えるのであれば、活性化関数は、
となるわけです。f(x)は入力された刺激を活性化関数で解釈し、軸索の太さである重みで補正した出力される刺激量です。このf(x)を次の結合しているニューロンの入力刺激xとすると、次のニューロンがまたそれを解釈してf(x)として出力する。この連続がニューロンの処理です。で、最終的には例えば「手を動かす」とか「思い出す」などの具体的な行動を起こす切っ掛けとなる刺激となります。
以上の事から、最低限ニューロンとして成立するには「入力刺激値」「活性化関数」「重み」「出力刺激値」が必要なのがわかります:
このたった一つのニューロンで学習が出来るのでしょうか?と言うか「そもそも学習って何?」って話です。
② 学習とは重みwの推定
上の最低限のニューロンは活性化関数A(x)と重みwだけで表現されています。この内活性化関数は通常何らかの固定した関数になります。となると、このニューロンの動作を規定するのは重みwだけになります。そこで、次のデータをご覧ください:
X0 X1 10 0 13 0 11 0 7 0
このデータのみからニューロンの重みwがどうなっているか想像できますでしょうか。どんな刺激X0が入ってきても、次の刺激は0…。そう、正解はw=0です。では次のデータ、
X0 X1 10 5 14 7 8 4 16 8
今度は入力された刺激が半分になって出力されています。これは活性化関数がA(x)=xとして、w=0.5かな~っと想像できますよね。そう、この入力刺激値からいい感じの出力刺激値を出してくれる重みwをデータから推測する事、これが「学習」なんです。これは沢山のニューロンが連なるニューラルネットワークでも同じです。数学的にはこれを「フィッティング問題」とか「曲線当てはめ問題」などと言います。
③ 最低限のニューロンをKerasで作る
①と②で実はもう学習するための最低限の条件が全部揃っています。①ではニューロンの刺激伝達を入力刺激値、活性化関数、重みそして出力刺激値を用いてモデル化しました。そして、それを数式で表す事も出来ました。②では対象となるデータを与えていますし、答えとなる重みを推測できる事も示しました。この青写真があれば、Kerasでそのモデルを作る事が出来ます。
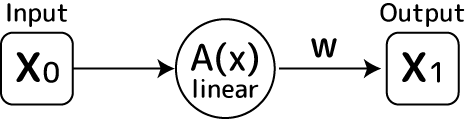
今回作成を試みるミニマムニューロンを図示化すると次のようになります:
この図の通りにkerasでプログラムを組んでみます。まず、動作するコードをご覧ください:
ミニマムニューロン import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import InputLayer
from keras import optimizers
import numpy
#モデル作成
model = Sequential()
model.add( InputLayer( input_shape = ( 1, ) ) )
model.add( Dense( 1, activation='linear' ) )
sgd = optimizers.SGD( learning_rate=0.001 ) # learning_rate(学習率)の設定は大切!
model.compile( loss = 'mse', optimizer = sgd, metrics=["accuracy"] )
#概略表示
model.summary()
#訓練開始
train_x0 = numpy.array( [ 10, 14, 8, 16 ] )
train_x1 = numpy.array( [ 5, 7, 4, 8 ] )
history = model.fit( train_x0, train_x1, epochs = 30 ) #epochs(繰り返し数)大切
#実用テスト
test_x0 = numpy.array( [ 200, 1000 ] )
res = model.predict( test_x0 )
print( res )
短い!いいね(^-^)。以下でこれをしっかり説明します。
〇 import
まずimport周りです。kerasは勿論入れましょうw。続くfrom~はここで使用するkerasの中に定義されているクラスを使いやすくしているだけです。これらクラスが出てきた所で説明しますね。numpyはデータを格納する配列で、格納したデータをkerasに渡すために使います。
〇 入力層
model = Sequential()
今回のミニマムなニューロンは[Input]→[linear]→[Output]と上から下へ刺激が真っ直ぐ一方通行に流れます。こういう真っすぐ流れるニューラルネットワークのモデルはKerasが用意するSequentialモデルで構築します。なのでmodelとしてそれを指定(生成)しています。
model.add( InputLayer( input_shape = ( 1, ) ) )
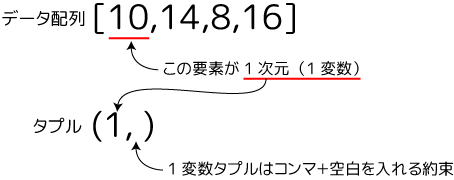
続いて各層を設定していきます。ミニマムニューロンの最初は入力層(Input)です。入力層は幾つか作り方があるのですが「InputLayer」というクラスを使うと明示的で分かりやすいです。今回の入力層には10とか14などの一つの刺激x0が入ってくるのでした。値が一つだけなので入力の型は「1次元要素」となります。その要素の型をモデルに教えているのがinput_shapeです。input_shapeにはタプルで要素の次元数を指定します:
このInputLayerをaddすると「入力層は1次元要素である」という事がmodel内に設定されます。
〇 中間層(ニューロン)
続いてニューロン本体である中間層(linear)の設定です:
model.add( Dense( units = 1, activation='linear' ) )
Denseクラスは「ニューロンは次の層にあるあらゆるニューロンに全部連結する」という全連結層を作る時に使います。生成する時に指定できるパラメータが沢山あるのですが、大切なのはunits(層内のニューロンの数)です。今回のミニマムニューロンは一つしかありませんから、この値は1となります。
層内のニューロンが採用する活性化関数はactivationで指定します。今回はA(x)=x、つまり線形関数を採用するのでした。Kerasには良く使う活性化関数がちゃんと用意されていて、線形関数は「linear」という名前で指定出来ます。これで「線形関数を活性化関数とする1つのニューロンだけが存在する中間層」が出来ました。
出力層ですが、今回は1つのニューロンが出力する刺激をそのまま採用します。その為「中間層=出力層」とみなせるため出力層を定義していません。「出力層は必ず指定しなければならない」という概念があったので、この辺り私もちょっと混乱てました。もし中間層の値をコンパクトにまとめる(中間層の出力と最終出力の形式が違う)場合は、それに合わせた出力層を追加する必要があります。
〇 最適化方法の指定
ここまででニューロンのモデリングはできました。続いて学習する元である重みを探す方法(=最適化法)を指定します。
sgd = optimizers.SGD( learning_rate=0.001 )
探し方の指定も沢山あるのですが、非常に良く使われるのが「SGD」です。これは「確率的勾配降下法(Stochastic Gradient Descent)」というもので、optimaizersという最適化方法を色々と指定できるモジュール内で定義されています。イメージするとこういう感じでしょうか:
重みwを色々と動かしてオレンジの球が一番底にくるwを探すのが最適化のイメージです。勾配降下法ではオレンジの球は坂の下に転がるように動きます。しかし、単純に転がすと球はすぐに途中の窪みにはまってしまいます。もっと最適な場所があるのに局所的な所に嵌る。その場所での重み(解)を「局所解」といます。モデルが複雑になると至る所局所解だらけになるので、より低い所が見つかりにくくなります。それを少しでも改善しようとしたのが確率的勾配降下法です。簡単に言えば「坂道が急な所は一気に降りちゃえ」という作戦です。そうすると、坂の途中にあるちょっとした窪みをすっとばす可能性(確率)が高まります。上の図だと真ん中のコブを越えられる訳です。そして坂が緩やかな場合はちょっとずつ進みます。坂の勾配に合わせて進む度合いを変化させる事で、効率化とより最適な解へ落ちる可能性を高める方法という訳です。
この確率的勾配降下法で坂道のきつさに対してどれだけ移動するかを指定するパラメータが「学習率(Lerning rate)」です。これは式を見た方が早いかなと思いますので、式を掲載します:
SGDの式は大よそ上のような形になっています。元の重みwを変化させて次の重みw'を求める式です。Q(w)はある重みwでの評価値で、上のグラフの縦軸に相当します。ΔQ(w)というのはそのw地点での坂道のきつさ(勾配)を表しています。坂がキツイ程ΔQ(w)の値は大きくなります(符号も考慮されます)。その勾配にηという値が掛け算されていますよね。これが学習率です。もしηが大きい値に設定されていたら、その分wは大きく動きます。逆に小さい値だとwはあまり大きく動かなくなります。ではどういうηが良いのかというと、これはケースバイケースで色々試す必要が実はあります。こういう元のデータからは推定できない学習率ηのようなパラメータの事を「ハイパーパラメータ」と呼びます。
SGDで学習率はlerning_rateで指定します。デフォルトは0.1のようですが、今回のデータセットではこの値は大きすぎて推定がぶっ飛んでしまいました。そこで0.001位にした所安定しました。学習率を調整する事が大切だ、という事ですね。
〇 モデルのコンパイル
モデルの形を決めて、最適化方法を定めたら、モデルをコンパイルできます。コンパイルによってモデルは初めて使えるようになります:
model.compile( loss = 'mse', optimizer = sgd, metrics=["accuracy"] )
コンパイル時にも幾つかパラメータを決める必要がありますが、必須となるのは「損失関数」と呼ばれる誤差を計算する方法です。これはlossに指定します。重みwの値が最適な値からずれていると、ニューロンは好ましくない刺激値を出力してしまいます。答えとなる値(X1)と出力値の違いがどれだけなのか?それを計るのが損失関数です。計り方にもいくつかありますが、上では"mse"というのを指定しています。これは「平均二乗誤差(Mean Square Error)」と呼ばれる統計量で、真の値と出力した値との差の2乗値の平均値を評価値とする方法です:
Keras内の計算式がこの通りの式では無いかもしれませんが、意味合いは多分一緒の式を掲載しました。出力された値xと真の値xiの差を取り、それを2乗します。データの個数分全部足し算するとMSEが算出されます。もし出力が大きくずれていたら、MSEの値はどーんと大きくなってしまいます。完全に一致していればMSEはゼロになります。一般にデータがモデルに完全にフィッティングする事はありませんので多少の誤差は絶対に出ます。ですからこのMSEがゼロになる、ではなくて最も小さくなる重みwが知りたい答えになります。
最適化方法はoptimizerに指定します。これには先に作成したsgdオブジェクトを直接渡せます。続くmetricsはログ出力する項目を指定するので必須ではありません。以上から、上のコードは「損失関数として平均二乗誤差を使い、最適化方法として確率的勾配降下法(SGD)を学習率ηを0.001で使う」という指定をしている事になります。
〇 学習
モデルをコンパイルしたらいよいよ学習です。
train_x0 = numpy.array( [ 10, 14, 8, 16 ] )
train_x1 = numpy.array( [ 5, 7, 4, 8 ] )
history = model.fit( train_x0, train_x1, epochs = 30 )
学習に必要なデータを用意します。train_x0は入力刺激値、train_x1は出力刺激値(=正解)です。今回のミニマムニューロンの入力刺激値は1次元変数でした。なので1次元配列を用意し、そこに入力刺激値を登録しています。今回のモデルは一つの刺激に対して一つ値を出力するので、各刺激値に1対1対応した出力刺激値も同様に一次元配列で指定しなければなりません。
データセットを用意したらfit関数で学習を開始出来ます。引数に入力刺激値と出力刺激値の配列を渡せばOKです。ただし、それだけだと一度しか学習してくれません。先の最適化を1回しか試行してくれないんです。その回数を指定するのがepochsです。これも決まった回数というのはありませんのでハイパーパラメータになります。
このコードが実行されると入力刺激値から出力刺激値が出てくるように重みを調整してくれます。
〇 実用テスト
学習が無事に終われば、何らかの調整が入った重みwがセットされたモデルが完成します。そこでモデルがいい感じで出力刺激値を出してくれるか実用テストしています:
test_x0 = numpy.array( [ 200, 1000 ] )
res = model.predict( test_x0 )
print( res )
テスト用の入力刺激値を配列で指定します。値は適当ですが、今回のミニマムモデルでは「入力刺激値の半分の値が出力される」事を期待しています。出力推定はpredict関数に入力刺激値を与えると行え、関数の戻り値に結果が返ってきます(今回の場合は要素が2つの1次元配列)。その結果をprint関数で出力すれば結果を目にする事が出来ます。
さて、以上最初に考えたミニマムなニューロンを再現するモデルをKerasで作ってみました。実際のこのコードを動作させると次のような出力を得られます:
Epoch 1/30
4/4 [==============================] - 0s 14ms/step - loss: 150.3720 - accuracy: 0.0000e+00
Epoch 2/30
4/4 [==============================] - 0s 750us/step - loss: 71.6191 - accuracy: 0.0000e+00
Epoch 3/30
4/4 [==============================] - 0s 750us/step - loss: 34.1108 - accuracy: 0.0000e+00
Epoch 4/30
4/4 [==============================] - 0s 500us/step - loss: 16.2464 - accuracy: 0.0000e+00
Epoch 5/30
4/4 [==============================] - 0s 746us/step - loss: 7.7380 - accuracy: 0.0000e+00
…省略…
Epoch 27/30
4/4 [==============================] - 0s 750us/step - loss: 3.7876e-04 - accuracy: 1.0000
Epoch 28/30
4/4 [==============================] - 0s 750us/step - loss: 3.7833e-04 - accuracy: 1.0000
Epoch 29/30
4/4 [==============================] - 0s 1ms/step - loss: 3.7807e-04 - accuracy: 1.0000
Epoch 30/30
4/4 [==============================] - 0s 750us/step - loss: 3.7790e-04 - accuracy: 1.0000
[[ 98.88426]
[494.1162 ]]
epochsで指定した回数だけ試行しています。lossの値が小さい程推定精度が高くなっている事を表します。最初は150.3720と誤差が大きいのですが、回を重ねるごとにみるみる減っているのがわかります。最後は誤差はかなり小さくなりました。そして実施テストの結果はというと、中々良い感じの値になっています!完全に半分の値にはなりませんが、たった4つの学習値だけでニューロンはちゃんと「元の値を半分くらいにすれば良いのかな?」と学習してくれたわけです。
巷に様々なKerasのサンプルコードがありますが、ここまでディープラーニングしていないミニマムなモデルはそうないんじゃないかなと思いますwww。でも、この位ベースから始めないとニューラルネットワークの仕組みやKerasのフレームワークを掴みきれないんじゃないかなと僕は感じています。というか、僕がそうです(^-^;。ここを起点として、少しずつディープの方向へ進んでいきましょう。